Ten basic algorithms you need to know about machine learning
Undoubtedly, as a subfield of artificial intelligence, machine learning has become more and more popular in the past few years. Since big data is currently the hottest trend in the technology industry, there is a huge potential for predicting and making recommendations based on large amounts of data machine learning. Some common examples of machine learning are: Netflix recommends videos based on movies you've seen before, or Amazon recommends books for you based on books you've bought before.
If you want to learn more about machine learning, where do you start? The author's first entry was to select a course on artificial intelligence when he exchanged overseas in Copenhagen. The lecturer of this course is a full-time professor of applied mathematics and computer science at the Technical University of Denmark. His research fields are mainly in logic and artificial intelligence. The main research content is the use of logic for computer-like human behavior ( Such as planning, reasoning, and problem solving. This course includes theory, core concepts, and hands-on problem solving. The textbooks used by the author are one of the classic textbooks in the field of artificial intelligence (AI): Peter Norvig's Artificial Intelligence — A Modern Approach, in which we learned several topics including: intelligent agents, solving through search Problem, Socialization AI, Philosophy / Sociology / Future of AI. At the end of the course, the authors use simple search-based agents to solve transmission problems in the virtual environment.
The author stated that he has learned a considerable amount of knowledge through this course and decided to continue studying this particular subject. In the next few weeks, the author participated in many technical lectures on machine learning, neural networks, and data architecture in San Francisco, especially a machine learning conference attended by many well-known scholars in the industry. Most importantly, the author selected an online course called "Introduction to Machine Learning" in Udacity and has recently completed his studies. In this article, the author shares the machine learning algorithms learned in the course.
Machine learning algorithms can be divided into three major categories: supervised learning, unsupervised learning, and reinforcement learning . among them:
Supervised learning is very effective for specific data sets (training sets) that are labeled, but it needs to predict for other distances.
Unsupervised learning is very useful for finding potential relationships on a given unlabeled data set (the goal is not specified in advance).
Reinforcement learning is somewhere in between—it has some form of feedback for each prediction step (or action), but there is no explicit mark or error message. This article focuses on 10 algorithms for supervised learning and unsupervised learning.
Supervised learning
1. Decision Trees :
A decision tree is a decision support tool that uses a tree or decision model and sequence possibilities. Including the consequences of various contingencies, resource costs, efficacy. The following figure shows its approximate principle:
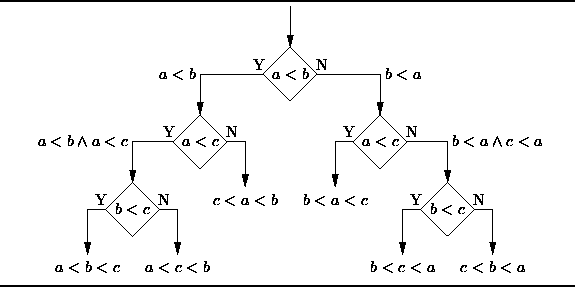
From a business decision point of view, in most cases the decision tree is the least likely way to evaluate the probability of making the right decision. It allows you to deal with this problem in a structured and systematic way, and then come to a logical conclusion.
2. Naive Bayesian classification:
Naive Bayes classification is a very simple classification algorithm. It is called Naive Bayes classification because the idea of ​​this method is really simple. Naive Bayes's ideological foundation is as follows: In the item, the probability of occurrence of each category under the condition of the occurrence of this item, which is the largest, is considered as which category the item to be classified belongs to.
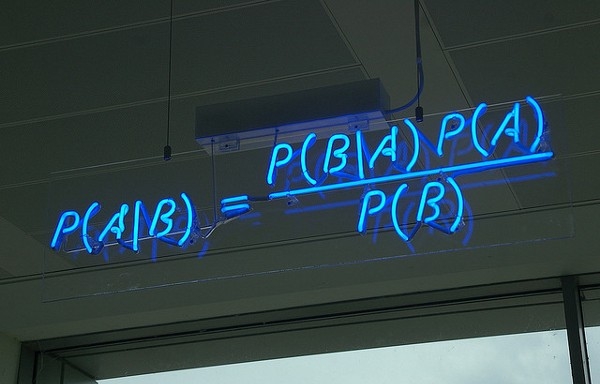
Examples of its use are:
Mark an email (or not) as spam
Classify a new article into science, technology, politics, or sports
Check whether a piece of text expresses positive or negative emotions
Face recognition software
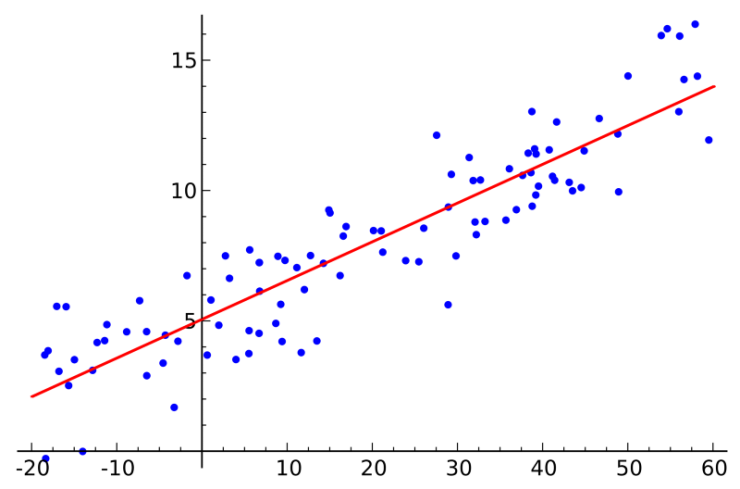
3. The least squares method (Ordinary Least Squares Regression):
If you know statistics, you may have heard about linear regression before. Least squares is a method of calculating linear regression. You can think of linear regression as the task of drawing a straight line in a series of points. There are many ways to do this, and the "least squares" method does this - you draw a line, then measure the vertical distance between the points and the lines for each data point, and add all these together, and the resulting simulation The line will be as small as possible over this total summed distance.
4. Logistic Regression:
Logistic regression is a powerful statistical method that can model a binomial result and one (or more) explanatory variables. It measures the relationship between the classification dependent variable and one (or more) independent variables by estimating the probability of using a logical operation, which is a cumulative logical distribution.
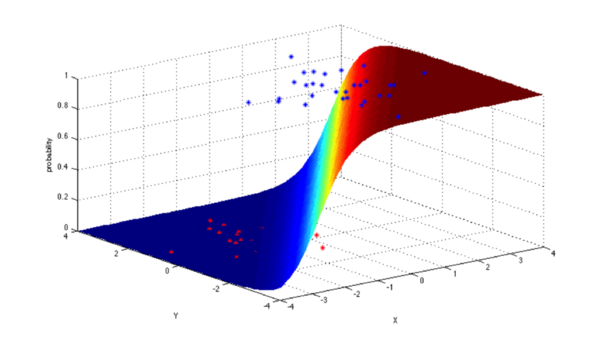
In general, logistic regression can be used for the following real application scenarios:
Credit score
Measuring the success rate of marketing campaigns
Predicting the revenue of a product
Is there an earthquake on a particular day?
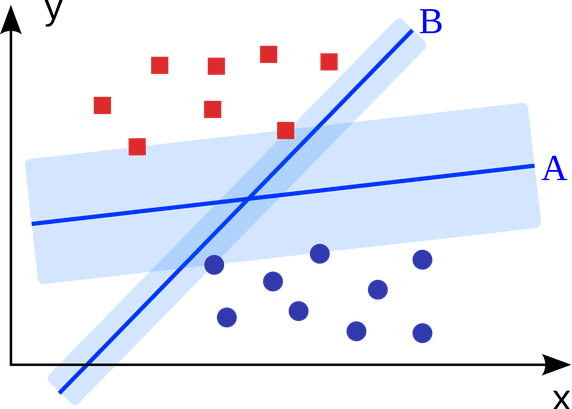
5. Support Vector Machine:
SVM (Support Vector Machine) is a binary classification algorithm. Given a set of 2 types of N-dimensional place points, a Support Vector Machine (SVM) generates a (N - 1)-dimensional hyperplane into these two groups. Suppose you have 2 types of points and they are linearly separable. SVM (Support Vector Machine) will find a straight line to divide these points into 2 types, and this line will be as far away from all points as possible.
In terms of scale, the biggest problem with the use of Support Vector Machine (SVM) (with appropriate modification) is display advertising, human splice site identification, image-based gender detection, and large-scale image classification.
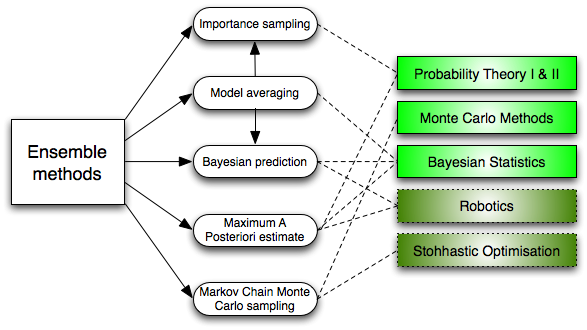
6. Ensemble methods:
The composition method is a learning algorithm that builds a series of classifications and then classifies new data points by taking a weighted voting prediction. The original integration method is the Bayesian averaging method, but recent algorithms include error correction output coding, bagging, acceleration, and the like.
How does the combined method work? Why are they better than other models? because:
They average deviations: If you average the Democratic polls and the Republican polls together, then you will get a balanced result without bias toward either side.
They reduce the difference: the summary opinions of a bunch of models are not as noisy as a single opinion of a model. In the financial sector, this is called diversification - there are many stock portfolios that have less uncertainty than a single stock, and that's why your model will be better for more data.
They are less likely to overfit: if you have independent models that are not overfitting, you combine the predictions of each independent model in a simple way (average, weighted average, logistic regression), which is unlikely to be Overfitting occurs.
Unsupervised learning
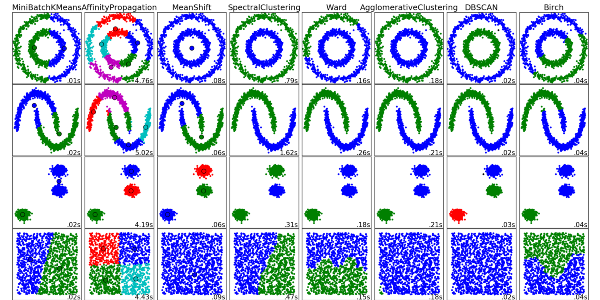
7. Clustering Algorithms:
Clustering is a task that aggregates objects. For example, objects in the same group (cluster) are more similar to each other than other different groups.
Each clustering algorithm is different, such as the following:
Centroid-based algorithm
Connection-based algorithm
Density-based algorithm
possibility
Dimension reduction
Neural network/deep learning
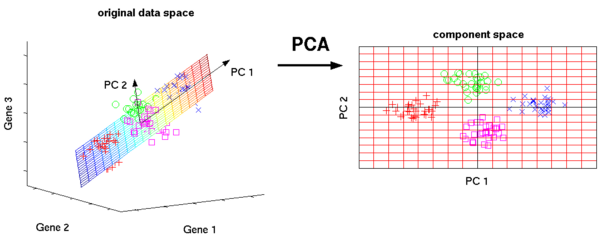
8. Principal Component Analysis (PCA):
Orthogonal transformation transforms a set of potentially relevant variables into a set of linearly uncorrelated variables. The transformed set of variables is called the principal component.
Some PCA program applications include compression, data reduction, and visualization. Note that it is very important to choose whether to use the domain of principal component analysis. When the data is noisy (the principal component analysis of all components has a fairly high variance), it is not suitable.
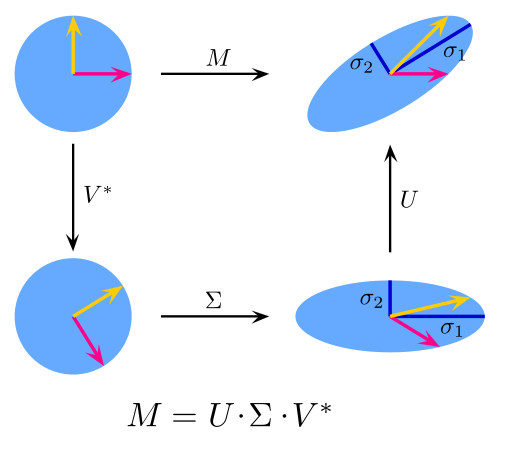
9. Singular Value Decomposition:
In linear algebra, SVD is a factorization of a very complex matrix. For a given m×n matrix M, there is a decomposition, M = UΣV, where u and v are a single matrix, and Σ is a diagonal matrix.
Principal component analysis PCA is a simple application of singular value decomposition SVD. In the field of computer vision, the first face recognition algorithm uses principal component analysis (PCA) which is a singular value decomposition (SVD) to represent faces as a linear combination of “feature faces,†and reduces dimensions, and then matches them by simple methods. Identity; While modern methods are more complex, many still rely on similar technologies.
10. Independent Component Analysis:
Independent Component Analysis (ICA) is a statistical technique that reveals hidden factors such as construction of random variables, technical measurements, and signals. The ICA defines the observed multivariate data generation model, which is usually given as a sample of a large database. In this model, the data variables are assumed to be a linear mixture of some unknown latent variables while the hybrid system is still unknown. Latent variables are assumed to be non-Gaussians and independent of each other. They are called independent components of the observed data.
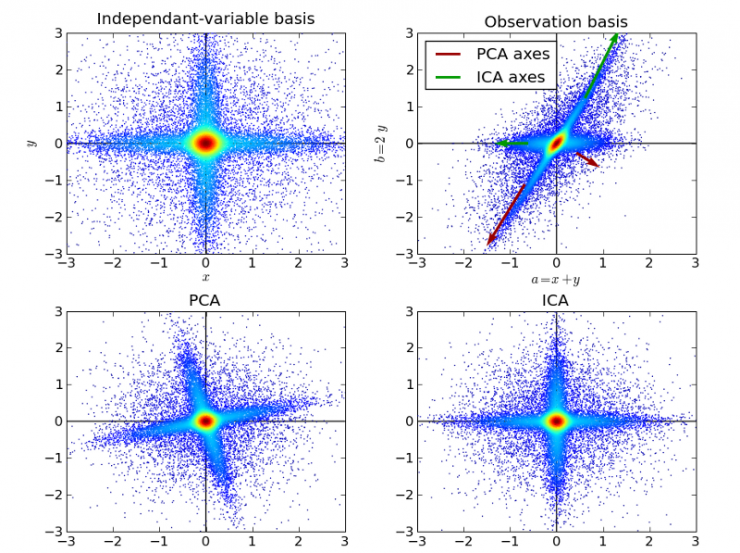
ICA is related to PCA but it is more powerful. When these classic methods fail completely, ICA can find potential sources of the source. Its applications include digital images, document databases, economic indicators and psychological tests.
Through the above introduction, I believe that most people have a certain understanding of machine learning algorithms. If you are interested in this aspect, you can then use your understanding of algorithms to create machine learning applications that will create better living conditions for people around the world.
PS : This article was compiled by Lei Feng Network (search “Lei Feng Network†public number) and it was compiled without permission.
Via LAB41