This is just a minimalist demo, designed to get to know the concept.
The word NoSQL is becoming ubiquitous in recent years. But what exactly is "NoSQL" referring to? How and why is it so useful? In this article, we will pass pure Python (I prefer to call it, "Light Structure" Pseudocode") Write a NoSQL database to answer these questions.
OldSQLIn many cases, SQL has become a synonym for "database." In fact, SQL is an acronym for Strutured Query Language, not the database technology itself. Rather, it refers to the RDBMS ( A relational database management system, a language for retrieving data. MySQL, MS SQL Server and Oracle are all part of the RDBMS.
R in the RDBMS, that is, "Relational" (relational, associated), is the most abundant part of the content. Data is organized by tables, each of which is a column associated with a type (type) ( Column). The type of all tables, columns, and their classes is called the schema of the database (schema or schema). The schema completely describes the structure of the database through the description of each table. For example, a table called Car may have The following columns:
Make: a string
Model: a string
Year: a four-digit number; alternate, a date
Color: a string
VIN(Vehicle Identification Number): a string
In a table, each single entry is called a row, or a record. To distinguish each record, a primary key is usually defined. The primary key in the table is one of the columns, which can uniquely identify Each row. In the table Car, VIN is a natural primary key choice because it guarantees that each car has a unique identifier. Two different rows may have the same value on the Make, Model, Year, and Color columns. But for different cars, there will definitely be different VINs. Conversely, as long as the two lines have the same VIN, we don't have to check other columns to think that these two lines refer to the same car.
Querying
SQL allows us to get useful information by querying the database. The query is simple, the query is to ask the RDBMS in a structured language, and interpret the returned rows as the answer to the question. Suppose the database represents For all registered vehicles in the US, in order to get all the records, we can do the following SQL query on the database:
SELECT Make, Model FROM Car;
Translate SQL roughly into Chinese:
"SELECT": "Show me"
"Make, Model": "Make and Model values"
"FROM Car": "Every line in the table Car"
That is, "Show me the value of Make and Model in each row of the table Car". After executing the query, we will get the results of some queries, each of which is Make and Model. If we only care about registration in 1994 The color of the car, then you can:
SELECT Color FROM Car WHERE Year = 1994;
At this point, we will get a list similar to the following:
Black
Red
Red
White
Blue
Black
White
Yellow
Finally, we can specify a car by using the primary key of the table, here VIN:
SELECT * FROM Car WHERE VIN = '2134AFGER245267'
The above query will return the attribute information of the specified vehicle.
The primary key is defined as unique and non-repeatable. That is, a vehicle with a specified VIN can only appear at most once in the table. This is very important, why? Look at an example:
RelationsSuppose we are running a car repair business. In addition to some other necessary things, we also need to track the service history of a car, that is, all the trim records on the car. Then we may create a ServiceHistory with the following columns table:
VIN | Make | Model | Year | Color | Service Performed | Mechanic | Price | Date
In this way, each time the vehicle is repaired, we add a new line to the table, and write about the service. What did we do, which repairman, how much and how long the service time.
But wait a minute, we all know that for the same car, all the information about the vehicle's own information is unchanged. In other words, if I trim my Black 2014 Lexus RX 350 10 times, then even if the information of Make, Model, Year and Color does not change, the information is recorded repeatedly every time. Compared with invalid duplicate records. A more reasonable approach is to store this information only once and query it when needed.
So what should I do? We can create a second table: Vehicle , which has the following columns:
VIN | Make | Model | Year | Color
In this way, for the ServiceHistory table, we can be reduced to the following columns:
VIN | Service Performed | Mechanic | Price | Date
You might ask, why does VIN appear in both tables at the same time? Because we need a way to confirm that the car in the ServiceHistory table refers to the car in the Vehicle table, that is, we need to confirm that the two records in the two tables represent the same car. In this case, we only need to store each car's own information once. Each time the vehicle comes to repair, we create a new row in the ServiceHistory table without having to add a new record to the Vehicle table. After all, they refer to the same car.
We can use the SQL query statement to expand the implicit relationship contained in the two tables of Vehicle and ServiceHistory:
SELECT Vehicle.Model, Vehicle.Year FROM Vehicle, ServiceHistory WHERE Vehicle.VIN = ServiceHistory.VIN AND ServiceHistory.Price > 75.00;
The query is designed to find Model and Year for all vehicles with a repair cost greater than $75.00. Notice that we match the records that meet the criteria by matching the VIN values ​​in the Vehicle and ServiceHistory tables. The returned records will be some of the two tables that meet the criteria. "Vehicle.Model" and "Vehicle.Year" mean that we only want these two columns in the Vehicle table.
If our database does not have indexes (the correct ones should be indices), the above query would need to perform a table scan to locate the rows that match the query requirements. The table scan checks each row in the table in order, which is usually very slow. In fact, table scan is actually the slowest of all queries.
You can avoid scanning the table by indexing the columns. We can think of the index as a data structure that allows us to quickly find a specified value (or some value within a specified range) on the indexed column by pre-sorting. That is, if we are in the Price column There is an index on it, so you don't need to scan the entire table line by line to determine whether the price is greater than 75.00, but only need to use the information contained in the index to "jump" to the first line with a price higher than 75.00. , and return each subsequent line (since the index is ordered, so the price of these lines is at least 75.00).
Indexing is an indispensable tool for increasing the speed of queries when dealing with large amounts of data. Of course, as with everything, there is a certain amount of loss. Using an index can lead to some extra consumption: The data structure of the index consumes memory, which can be used to store data in the database. This requires us to weigh the pros and cons and seek a compromise, but it is very common to index the columns that are frequently queried.
The Clear Box
Thanks to the database's ability to examine the schema of a table (depicting what type of data each column contains), advanced features like indexes can be implemented and can make a reasonable decision based on the data. In other words, for a database, a table is actually an antonym of a "black box" (or a transparent box)?
Keep this in mind when we talk about NoSQL databases. This is also a very important part when it comes to querying the capabilities of different types of database engines.
SchemasWe already know that the schema of a table describes the name of the column and the type of data it contains. It also includes other information, such as which columns can be empty, which columns do not allow duplicate values, and other restrictions on the columns in the table. A table can only have one schema at any time, and all rows in the table must comply with the schema.
This is a very important constraint. Suppose you have a database of tables with millions of consumer information. Your sales team wants to add additional information (for example, the age of the user) to improve the accuracy of their email marketing algorithms. This requires an alter table to be added — add a new column. We also need to decide if each row in the table requires that the column must have a value. Often, it makes sense to have a column with a value, but doing so may require information that we can't easily get (such as the age of each user in the database). Therefore, at this level, some trade-offs are also needed.
In addition, making changes to a large database is usually not a trivial matter. In order to prevent errors, it is very important to have a rollback solution. But even so, once the schema is changed, we are not always able to revoke these changes. Maintenance of the schema may be one of the most difficult parts of the DBA's work.
Key/Value Stores
Prior to the word "NoSQL", key/Value Data Stores like memcached provided data storage without the need for a table schema. In fact, there is no concept of "table" at all when K/V is stored. There are only keys and values. If the key-value store sounds familiar, it may be because the concept of the concept is consistent with Python's dict and set: using a hash table to provide a basis Fast data query for keys. A primitive Python-based NoSQL database, in simple terms, is a large dictionary.
In order to understand how it works, hand-write one automatically! Let's first look at some simple design ideas:
a Python dict as the primary data store
Only string type is supported as a key (key)
Support for storing integer, string and list
A simple TCP/IP server using ASCLL string to deliver messages
Some advanced commands like INCREMENT, DELETE, APPEND, and STATS (command)
One advantage of having an ASCII-based TCP/IP interface for data storage is that we can interact with the server using a simple telnet program and don't need a special client (although this is a very good exercise and only needs 15 lines of code can be done).
For the return information we send to the server and other, we need a "wired format". Here's a simple description:
Commands Supported
PUT
Parameters: Key, Value
Purpose: Insert a new entry into the database
GET
Parameters: Key
Purpose: Retrieve a stored value from the database
PUTLIST
Parameters: Key, Value
Purpose: Insert a new list entry into the database
APPEND
Parameters: Key, Value
Purpose: Add a new element to an existing list in the database
INCREMENT
Parameters: key
Purpose: To grow an integer value in the database
DELETE
Parameters: Key
Purpose: Delete an entry from the database
STATS
Parameters: None (N/A)
Purpose: Request statistics for success/failure of each executed command
Now let's define the structure of the message itself.
Message StructureRequest Messages
A Request Message contains a command (command), a key (key), a value (value), and a type of value. The last three types are optional, non-essential. ; is used as a separator. Even if the above options are not included, there must still be three characters in the message;
COMMAND; [KEY]; [VALUE]; [VALUE TYPE]
COMMAND is one of the commands in the list above
KEY is a string that can be used as a database key (optional)
VALUE is an integer in the database, list or string (optional)
List can be represented as a string separated by commas, for example, "red, green, blue"
VALUE TYPE describes why VALUE should be interpreted why
Possible type values ​​are: INT, STRING, LIST
Examples
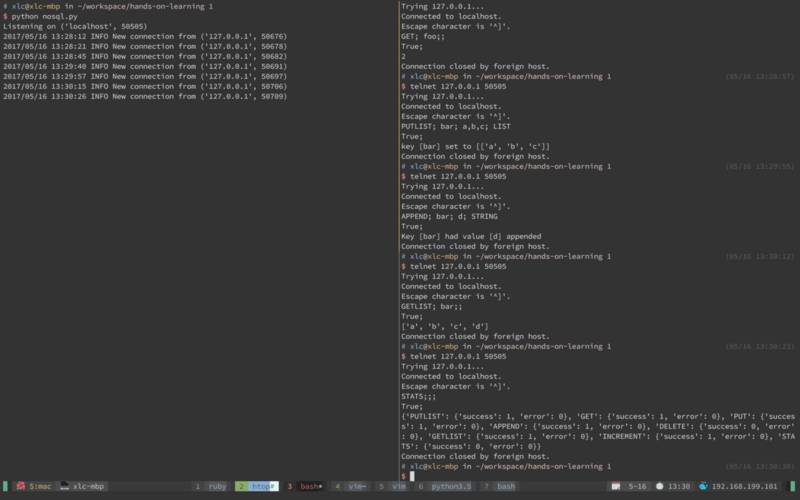
"PUT; foo; 1; INT"
"GET; foo;;"
"PUTLIST; bar; a,b,c ; LIST"
"APPEND; bar; d; STRING"
"GETLIST; bar; ;"
STATS; ;;
INCREMENT; foo;;
DELETE; foo;;
Reponse Messages
A response message (Reponse Message) consists of two parts, separated by ; The first part is always True|False , which depends on whether the command being executed was successful. The second part is the command message, and when an error occurs, an error message is displayed. For those commands that execute successfully, if we don't want the default return value (such as PUT), a success message will appear. If we return the value of a successful command (such as GET), then the second part will be its own value.
Examples
True; Key [foo] set to [1]
True; 1
True; Key [bar] set to [['a', 'b', 'c']]
True; Key [bar] had value [d] appended
True; ['a', 'b', 'c', 'd']
True; {'PUTLIST': {'success': 1, 'error': 0}, 'STATS': {'success': 0, 'error': 0}, 'INCREMENT': {'success': 0, 'error': 0}, 'GET': {'success': 0, 'error': 0}, 'PUT': {'success': 0, 'error': 0}, 'GETLIST': {'success ': 1, 'error': 0}, 'APPEND': {'success': 1, 'error': 0}, 'DELETE': {'success': 0, 'error': 0}}
Show Me The Code!
I will show all the code in the form of a block summary. The entire code is only 180 lines, and it won't take long to read.
Set Up
Here are some of the boilerplate code we need for our server:
"""NoSQL database written in Python"""
# Standard library imports
Importophone
HOST = 'localhost'
PORT = 50505
SOCKET = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
STATS = {
'PUT': {'success': 0, 'error': 0},
'GET': {'success': 0, 'error': 0},
'GETLIST': {'success': 0, 'error': 0},
'PUTLIST': {'success': 0, 'error': 0},
'INCREMENT': {'success': 0,'error': 0},
'APPEND': {'success': 0, 'error': 0},
'DELETE': {'success': 0, 'error': 0},
'STATS': {'success': 0, 'error': 0},
}
It's easy to see that the above is just a package import and some data initialization.
Set up(Cont'd)
Next I will skip some code so I can continue to show the rest of the code in the preparation section above. Note that it involves some functions that don't exist yet, but that's okay, we'll cover later. In the full version (which will be presented at the end), everything will be organized in an orderly manner. Here is the remaining installation code:
COMMAND_HANDERS = {
'PUT': handle_put,
'GET': handle_get,
'GETLIST': handle_getlist,
'PUTLIST': handle_putlist,
'INCREMENT': handle_increment,
'APPEND': handle_append,
'DELETE': handle_delete,
'STATS': handle_stats,
}
DATA = {}
Defmain():
"""Main entry point for script"""
SOCKET.bind(HOST,PORT)
SOCKET.listen(1)
While1:
Connection,address = SOCKET.accept()
Print('New connection from [{}]'.format(address))
Data = connection.recv(4096).decode()
Command,key,value = parse_message(data)
Ifcommand == 'STATS':
Response = handle_stats()
Elifcommand in('GET','GETLIST','INCREMENT','DELETE'):
Response = COMMAND_HANDERS[command](key)
Elifcommand in(
'PUT',
'PUTLIST',
'APPEND',):
Response = COMMAND_HANDERS[command](key,value)
Else:
Response = (False, 'Unknown command type {}'.format(command))
Update_stats(command,response[0])
Connection.sandall('{};{}'.format(response[0],response[1]))
Connection.close()
If__name__ == '__main__':
Main()
We created COMMAND_HANDLERS, which is often referred to as a look-up table. The job of COMMAND_HANDLERS is to associate commands with the functions used to process the command. For example, if we receive a GET command, COMMAND_HANDLERS[command](key) is equivalent to handle_get(key) . Remember, in Python, a function can be thought of as a value and can be like any other value. Stored in a dict.
In the above code, although some commands request the same parameters, I still decided to process each command separately. Although it is simple and rude to force all handle_ functions to accept a key and a value, I hope that these handlers are more organized, easier to test, and less likely to cause errors.
Note that the socket-related code is very minimal. Although the entire server is based on TCP/IP communication, there is not much underlying network interaction code.
Finally, there is a small point to note: the DATA dictionary, because this point is not very important, so you are likely to miss it. DATA is the key-value pair that is actually stored, and it is they that actually make up our database.
Command Parser
Let's look at some command parser, which is responsible for interpreting the received message:
Defparse_message(data):
"""Return a tuple containing the command, the key, and (optionally) the
Value cast to the appropriate type."""
Command,key,value,value_type = data.strip().split(';')
Ifvalue_type:
Ifvalue_type == 'LIST':
Value = value.split(',')
Elifvalue_type == 'INT':
Value = int(value)
Else:
Value = str(value)
Else:
Value = None
Returncommand,key,value
Here we can see that a type conversion has occurred. If we want the value to be a list, we can get the value we want by calling str.split(',') on the string. For int, we can simply use int() with argument as string. The same is true for strings and str().
Command Handlers
Below is the code for the command handler. They are all very intuitive and easy to understand. I noticed that although there are a lot of error checks, they are not all-inclusive and very complicated. In the process of reading, if you find any errors, please move on to discuss.
Defupdate_stats(command,success):
"""Update the STATS dict with info about if executing *command* was a
*success*"""
Ifsuccess:
STATS[command]['success'] += 1
Else:
STATS[command]['error'] += 1
Defhandle_put(key,value):
"""Return a tuple containing True and the message to send back to the
Client."""
DATA[key] = value
Return(True,'key [{}] set to [{}]'.format(key,value))
Defhandle_get(key):
"""Return a tuple containing True if the key exists and the message to send
Back to the client"""
Ifkey notinDATA:
Return(False,'Error: Key [{}] not found'.format(key))
Else:
Return(True,DATA[key])
Defhandle_putlist(key,value):
"""Return a tuple containing True if the command succeeded and the message
To send back to the client."""
Returnhandle_put(key,value)
Defhandle_putlist(key,value):
"""Return a tuple containing True if the command succeeded and the message
To send back to the client"""
Returnhandle_put(key,value)
Defhandle_getlist(key):
"""Return a tuple containing True if the key contained a list and the
Message to send back to the client."""
Return_value = exists, value = handle_get(key)
Ifnotexists:
Returnreturn_value
Elifnotisinstance(value,list):
Return(False,'ERROR: Key [{}] contains non-list value ([{}])'.format(
Key,value))
Else:
Returnreturn_value
Defhandle_increment(key):
"""Return a tuple containing True if the key's value could be incremented
And the message to send back to the client."""
Return_value = exists, value = handle_get(key)
Ifnotexists:
Returnreturn_value
Elifnotisinstance(list_value,list):
Return(False,'ERROR: Key [{}] contains non-list value ([{}])'.format(
Key,value))
Else:
DATA[key].append(value)
Return(True,'Key [{}] had value [{}] appended'.format(key,value))
Defhandle_delete(key):
"""Return a tuple containing True if the key could be deleted and the
Message to send back to the client."""
Ifkey notinDATA:
Return(
False,
'ERROR: Key [{}] not found and could not be deleted.'.format(key))
Else:
DelDATA[key]
Defhandle_stats():
"""Return a tuple containing True and the contents of the STATS dict."""
Return(True,str(STATS))
There are two things to note: multiple assignments and code reuse. Some functions are just simple wrappers for existing functions for more logic, such as handle_get and handle_getlist. Since we sometimes just need an existing function The return value, but at other times you need to check what the function returns, and then use multiple assignments.
Let's take a look at handle_append . If we try to call handle_get but the key doesn't exist, then we simply return what the handle_get returns. In addition, we also want to be able to reference the tuple returned by handle_get as a separate return value. Then when the key does not exist, we can simply use return return_value.
If it does exist, then we need to check the return value. Also, we want to be able to reference the return value of handle_get as a separate variable. In order to be able to handle both cases, and consider the case where we need to separate the results separately, we use multiple assignments. This way, you don't have to write multiple lines of code while keeping the code clear. Return_value = exists, list_value = handle_get(key) can explicitly indicate that we are going to reference the return value of handle_get in at least two different ways.
How Is This a Database?The above program is obviously not an RDBMS, but it is definitely a NoSQL database. The reason it's so easy to create is that we don't have any actual interaction with data. We just did a minimal type check to store whatever the user sent. If we need to store more structured data, we might need to create a schema for the database to store and retrieve data.
Since NoSQL databases are easier to write, easier to maintain, and easier to implement, why don't we just use mongoDB? Of course, there is a reason, or that sentence, there must be some loss, we need to weigh the database searchability (searchability) based on the data flexibility provided by the NoSQL database.
Querying Data
Suppose we have the NoSQL database above to store the previous Car data. Then we might use VIN as the key, use a list as the value for each column, that is, 2134AFGER245267 = ['Lexus', 'RX350', 2013, Black] . Of course, we have lost every index in the list. Meaning. We only need to know that index 1 stores the model of the car somewhere, and index 2 stores Year.
The bad thing is coming, what happens when we want to execute the previous query? Finding the colors of all the cars in 1994 will be a nightmare. We must iterate through each value in DATA to see if the value stores car data or other unrelated data, such as checking index 2, seeing if index 2 is equal to 1994, and then continuing to take index 3 Value. This is worse than table scan because it not only scans every row of data, but also applies some complicated rules to answer the query.
The authors of the NoSQL database are of course aware of these issues (since the query is a very useful feature) and they have come up with ways to make the query less "unreachable." One way is to structure the data used, such as JSON, to allow references to other rows to represent relationships. At the same time, most NoSQL databases have the concept of a namespace. A single type of data can be stored in a "section" unique to that type in the database, which allows the query engine to take advantage of the "shape" of the data being queried. information.
Of course, although some more complex methods already exist (and are implemented) to enhance queryability, it is always an inevitable problem to compromise between storing a smaller number of schemas and enhancing queryability. In this case our database only supports queries via key. If we need to support richer queries, things will get a lot more complicated.
SummaryAt this point, I hope that the concept of "NoSQL" is already very clear. We learned a bit of SQL and learned how the RDBMS works. We saw how to retrieve data from an RDBMS (using SQL queries). By building a toy-level NoSQL database, we learned about some of the problems between queryability and simplicity, and also discussed some databases. Some of the methods used by the author to address these issues.
Even with simple key-value storage, knowledge about databases is vast. Although we only explored the stars, we still hope that you have already understood what NoSQL means, how it works, and when it works. If you want to share some good ideas, welcome to discuss.
Fan Motor,Blower Motor,Condenser Fan,Condenser Fan Motor
Wentelon Micro-Motor Co.,Ltd. , https://www.wentelon.com