Author: Bougas Pavlos, Iliopoulos Marios
introduction
Initially, electrical appliances such as TVs, set-top boxes, and air conditioners only required a small amount of control functions [1]. In most cases, an on/off button, a few selection buttons, and two sets of increase/decrease controls are sufficient to fully control your device.
But as the functions supported by the device increase, the commands and configuration options used by the user also increase. However, users still want to use only one remote control to manage all functions. To solve this problem, engineers began to integrate more complex user interfaces (UI). The hierarchical menu appears on the TV screen, and more and more buttons are filled into the remote control so that the user can call and browse the menu.
Today's important trend is to make devices more "smart". Smart devices can be connected to other devices and the Internet to provide more functions and services. It is impractical and not a pleasant experience to use the menu to browse and use the small button keys on the remote control to enter a large string.
In this article, we will discuss how to use voice commands to provide a better user experience. We especially studied the DA14585-based advanced voice remote control reference design using Dialog to implement voice commands through Bluetooth Low Energy (BLE).

Figure 1 Larger QWERTY remote control
Use voice as a command interface
Voice is a very powerful and intuitive interface. A simple phrase can contain enough information to describe a very complex command. However, capturing phrases and extracting meaningful information (usually in the form of strings) in a noisy environment is a technical challenge. Fortunately, the source of this demand, that is, the connection of smart devices to the Internet, also provides a solution to this complex problem. Devices can now access cloud computing and can benefit from the most advanced speech-to-text recognition engines, such as technologies provided by companies such as Nuance Communications, Microsoft, Google, and Amazon. Today, cloud-based speech recognition services are sufficient to provide a very good user experience.
Why do we need a remote control?
In fact, the solution to continuously monitor voice commands was developed very early. The device can constantly listen to the surrounding sounds and search for commands. However, background noise and the distance between the user and the microphone make it difficult to correctly identify the information. In addition, the amount of data exchanged between devices and cloud services is huge, and speech recognition engines face a large number of requests, most of which are irrelevant. The continuous recording of environmental sounds also brings serious security and privacy risks.
We need a kind of trigger, usually through buttons, gestures, or recognizable words or phrases. This solution is suitable for users and devices that are very close, such as smart phones. However, in smart TVs, set-top boxes, and other applications where users are far away from the device, it is much more difficult to correctly identify the trigger signal and provide a good user experience. The microphone needs to be close to the user, doesn't it have a remote control? Then embedding the microphone into the remote control couldn't be more natural.
Quantify speech recognition requirements
In simple terms, the challenge of the voice command function can be expressed as: "Capture'enough' high-quality voice records, send them to the voice recognition engine, and then process the text results to get the user's commands." This phrase contains two basic requirements. The first is the need for triggers. In fact, two triggers are needed: the first indicates the beginning of the command, and the second indicates the end.
The second set of requirements is related to the audio signal itself. Voice recording should be encoded in a format suitable for engine processing, and the quality should be "enough". How to define “enough†quality? The Android compatibility definition document [2] introduces some ideas about audio capture quality indicators.
The frequency response should remain almost flat (+/- 3 dB) over the speech spectrum from 100 Hz to 4000 Hz. This is a well-known specification for describing narrowband speech signals. Regarding the signal level generated by the microphone, the Android Compatibility Guide defines a single point in the sound power level-RMS graph and the range of linearly tracking the sound power level.
For a sound with a sound pressure level (SPL) of 90 dB at 1 kHz, for a 16-bit PCM signal, it should produce 2500 RMS. This is almost 10% of the overall amplitude range of the 16-bit signed signal. To get a feel for the SPL range, a normal level television or typical human conversation can produce 60 dB SPL within a distance of 1 meter. In contrast, diesel trucks produce 90 dB SPL at a distance of 10 meters.
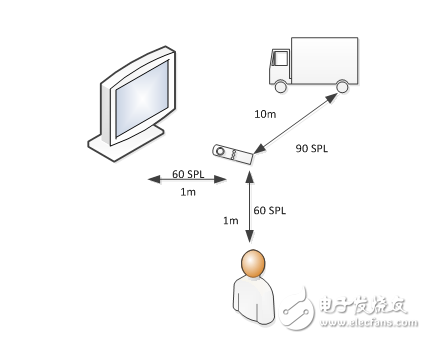
Figure 2. Example of sound pressure level
Of course, we cannot expect users to place the microphone in a precise position and speak at a specific volume level whenever they want to use voice commands. Since the PCM amplitude level can be tracked linearly, the speech recognition engine can work at a range of different sound pressure levels. A range of at least 30 dB is required. Starting from the 90 dB SPL point, the microphone should at least track linearly from -18 dB to +12 dB; therefore, it is between +72 dB SPL and +108 dB SPL. This is equivalent to placing the microphone between 0.8 cm and 25 cm from the mouth and speaking at normal intensity.
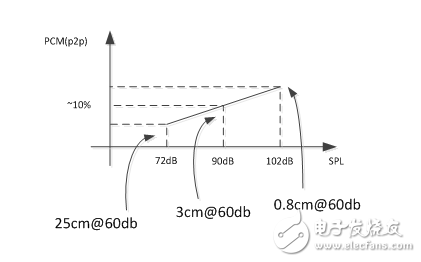
Figure 3. PCM to SPL coordinate map
The speech recognition engine seems to be more sensitive to nonlinear behavior. For a 1 kHz sine wave with a 90 dB SPL input level on the microphone, the total harmonic distortion should be less than 1%. Noise reduction processing and automatic gain control (if present) must be disabled.
other requirements
People who have used wireless audio protocols in the past are usually more skeptical of using data-oriented protocols to transmit voice commands, such as Bluetooth Low Energy.
Transmitting voice commands is slightly different from transmitting real-time audio or human voice (such as a telephone conversation). Since users don't have to listen to their voices or maintain a conversation, the delay requirements can be relaxed, because fixed and within a certain range of delays are inevitable. However, the data loss requirement is very strict, because the lack of audio clips may make the speech recognition engine unable to successfully extract the user's initial information. Of course the machine can ask you to repeat this information, but this is not the experience people want.
Build a voice command remote
Now we look at the architecture of the voice command remote control, we will follow the path of the audio signal through the system. In this process, we will focus on the challenges that are often encountered in the realization of a cost-effective, power-efficient voice remote control, and possible solutions.
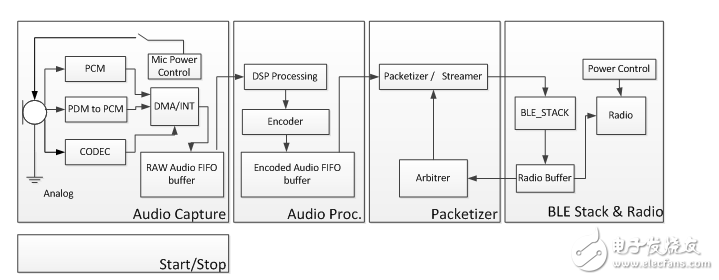
Figure 4. Typical voice capture signal path
It all starts with the audio capture subsystem. This can be based on inexpensive analog microphones and codec circuits, or digital microphones, to digitize the samples and transmit them according to known serial protocols.
For battery-powered systems (such as voice command remote controls), minimizing power consumption is essential. Therefore, it is strongly recommended to power gating the power of external components such as microphones or external codecs.
The audio sampling rate must be at least 8k Samples/s to meet the 4 kHz audio bandwidth requirement. However, 16k Samples/s with at least 16 bits per sample is a more conventional choice. The use of 16-bit sampling can ensure a sufficient sound pressure level range, so that the captured audio signal will contain enough information for the speech-to-text recognition to proceed normally.
Sampling audio involves interrupts or some form of hardware DMA to obtain samples and transfer them to a buffer. This buffer needs to decouple strictly timed audio samples from subsequent audio processing. For low-cost devices, audio processing is handled by the same processor of the service application, and in some cases by the BLE protocol stack. Therefore, the size of the buffer will depend on the maximum expected time required for the audio processing module to access the CPU, process the audio data, and move it to the next step. The typical time is within a few milliseconds. For a 16-bit 16k Samples/s signal, 32 bytes are generated per millisecond, and a 160-200 byte buffer is generally sufficient to allow processing time within 5 milliseconds.
The audio processing module implements simple audio processing and encodes audio data to reduce its overall rate. Audio processing includes very basic filtering, such as DC offset cancellation or band-pass filtering, and fixed gain to optimize audio amplitude. The original audio data is 256 kbit/s, and data can be streamed with margin through BLE. In order to reduce the rate and make better use of the bandwidth, the audio is encoded using known audio compression algorithms. The choice of encoder is more diverse, from simple fixed-rate lossy codecs (such as IMA-ADPCM) to complex processing-intensive fixed or variable-rate algorithms (such as OPUS). A simple codec can run on a CPU with a lower MIPS capacity, but at the same output bit rate, the resulting audio stream is of lower quality. On the other hand, complex algorithms can improve the quality of encoded audio streams, but require a more expensive and power-intensive CPU.
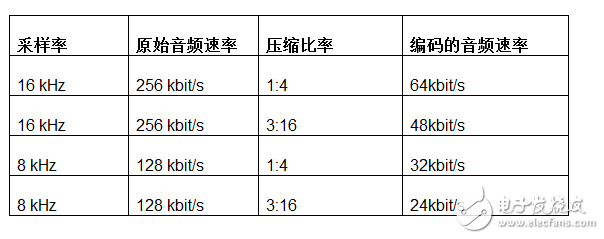
The output of the encoder contains the final payload that needs to be transmitted wirelessly, and an additional buffer is needed to help balance the instantaneous RF data rate with the average output rate of the encoder. The output rate of the encoder is equal to the sampled audio rate divided by the achieved compression ratio. The following table shows the typical raw and encoded audio rates supported by Dialog's Voice RCU reference design.
Table 1. Raw and IMADPCM encoded audio
BLE is a packet-based protocol that exchanges data packets at specific points in time, separated by regular connection intervals. If interference occurs during the meeting point to distort the data packet, the data will be retransmitted in the next data packet. Each connection interval occurs in a different frequency channel. Generally, interfering signals often appear in a frequency range, distorting multiple connection events and significantly reducing bandwidth.
BLE provides a mechanism called channel mapping update to solve this problem. The master device will detect the affected frequency range and implement the channel mapping update procedure. Prior to this, BLE connections may experience a significant drop in RF data rate. The size of the buffer at the output of the encoder should be adjusted accordingly to be able to withstand such events. The size adjustment can use ultra-safe methods, such as buffering complete 5 seconds of information requires 40k bytes, or buffering for 5 seconds at half the rate without losing any data, which requires a 20k byte buffer. Considering the equipment available on the market, this is a very difficult requirement to meet. The entire protocol stack and application programs of most devices have only 20-40 kbytes of total available RAM. This resource cannot be wasted on a single buffer. It should be noted that the size of the buffer is directly proportional to the encoder output rate and the time to ensure that data is not lost.
Many technologies have been proposed on the market, which can be used alone or in combination to solve this problem without a large buffer. Increase the RF output power when streaming audio samples to minimize interference; quickly fine-tune the channel mapping; use more sophisticated encoders to reduce the required RF data rate, or even dynamically when a significant RF bandwidth drop is detected Reduce quality. Each technology deals with the problem at the expense of certain other resources (such as energy consumption, CPU usage, or audio quality) instead of using more RAM.
Depending on the encoder algorithm used, the data can be stored as a continuous stream or as a list of packets with a predefined length. In order to make better use of the BLE bandwidth, it is best to treat the data as a data stream that is not packetized by the encoder. The lossless nature of BLE transmission ensures that we can always reconstruct our initial data stream on the remote control. Multiple BLE connection parameters-connection interval, ATT_MTU size, data channel PDU size, and connection event length-will affect the choice of the theoretical optimal size of BLE data packets. At runtime, the actual error rate may require further optimization of the packet size. Since the time required for the gap between the remote control response and the data packet is eliminated, using a larger data PDU can effectively double the effective data rate. On the other hand, the transmission time of a single data packet is extended, which increases the possibility of errors and retransmission costs during the transmission of the data packet. In an environment with severe wireless pollution, using a smaller data PDU may be more effective than using the largest protocol data unit communicated.
All these requirements determine the emergence of the smart module. The smart module extracts data from the encoded stream, packs the data according to the connection characteristics, and pushes it into the BLE protocol stack, while monitoring the actual BLE data rate and error rate. The packer should also have some form of arbitration and flow control to avoid excessive data flooding into the BLE protocol stack, and reserve enough bandwidth for other applications to use BLE for data exchange during audio transmission to ensure that the device does not There will be no response.
Dialog advanced voice remote control solution
To allow designers to evaluate the performance of a fully functional voice command remote control, Dialog provides an advanced voice remote control reference design based on a single DA14585 Bluetooth Low Energy (BLE) SoC. The design not only supports voice, but also supports a series of additional functions, such as wireless mouse, touchpad, infrared, and buttons. These functions are all present in modern remote control designs, providing users with a more natural way to interact with terminal devices and browse menus And results.

Figure 5. Dialog voice remote control development kit
The second-generation reference design includes important changes in the entire software architecture, making it more modular and easier to adapt to the requirements of the final product. All functions are organized into modules, with platform-related and independent parts. These modules are connected to the driver for the DA14585 internal peripherals or external components selected for the Dialog advanced voice remote control development board.
The audio path is constructed according to the principles introduced earlier.
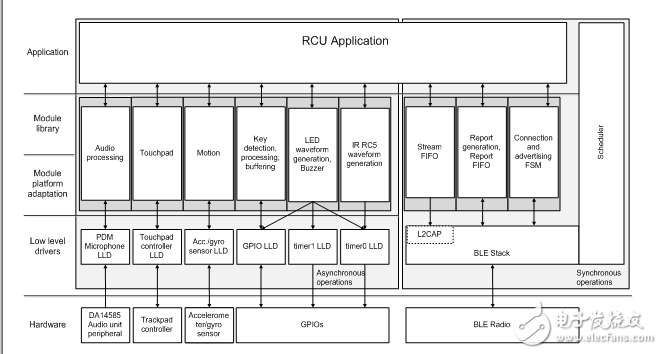
Figure 6. System architecture of Dialog voice remote control solution
In order to improve audio quality, the design uses a digital microphone. For cost-sensitive applications, PDM microphones are more suitable than I2S/PCM. The integrated PDM-PCM converter of DA14585 converts high-frequency PDM signals into 24-bit audio PCM samples, and transmits them to the memory buffer through a dedicated DMA channel.
The M0 CPU executes audio processing and streaming modules. From the main loop, call a preprocessing module to apply DC blocking and 24-bit to 16-bit conversion. If needed, the down-sampling unit can reduce the audio sample rate from 16k Samples/s to 8k Samples/s. The result of the audio preprocessing unit is fed to the IMA ADPCM encoder. Depending on the configuration, the encoder generates a 4-bit or 3-bit sample for each 16-bit audio sample.
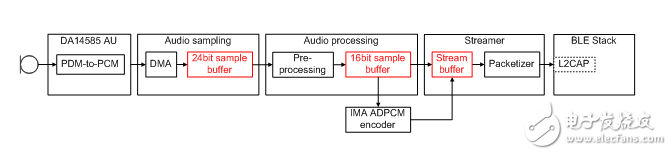
Figure 7. Audio path of the Dialog voice remote control solution
As a design choice, the reference design supports an adaptive audio rate mechanism to prevent possible buffer underruns. The sampling rate of audio samples and/or the configuration of the IMA ADPCM encoder can be changed at any time, so that you can switch between different output rates. To support this mechanism, an in-band signaling mechanism has been developed. The output of the encoder and the in-band signaling share the same data stream buffer.
The packer module collects data from the data stream buffer and pushes them into the protocol stack efficiently, while trying not to overflow. In addition to considering connection parameters, the packer also closely monitors the error rate and instantaneous available bandwidth. This helps it make a decision whether to reduce or improve audio quality when the adaptive audio rate mechanism is enabled.
All strategies, such as the use of fixed or adaptive audio rates, and the way audio starts and stops, are controlled by the user or remote device. The individual buffer size is a configuration option, because it may be suitable for different user experiences depending on the final application.
in conclusion
The ability to connect devices to the Internet, combined with modern cloud-based voice recognition services, enables a powerful new user interface-voice commands. Smart phones, smart TVs and set-top boxes are already using voice commands. By integrating low-cost microphones into BLE-connected peripherals, the user's voice recognition experience can be greatly enhanced. Commands collected from remote controls, smart watches, and wearable devices are transmitted to the voice recognition engine in the cloud through smart devices, which can control the smart device itself and peripheral devices connected to the smart device or other devices controlled by the voice assistant.
Welding diodes are available for medium frequency (over 2KHz) and high frequency (over 10khz) applications.They have very low on - state voltage and thermal resistance. Welding diodes are designed for medium and high frequency welding equipment and optimized for high current rectifiers. The on-state voltage is very low and the output current is high.
Welding Diode,Disc Welding Diode,3000 Amp Welding Diode,High Current Rectifier Welding Diode
YANGZHOU POSITIONING TECH CO., LTD. , https://www.cnpositioning.com