Abstract
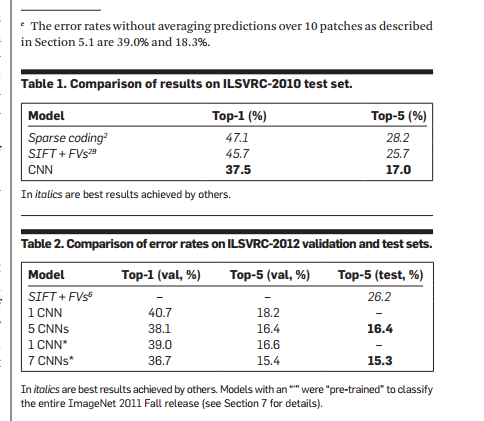
On the LSVRC-2010 dataset, we trained 1.2 million high-resolution images divided into 1000 categories. Top-1 was obtained on the test set, and the top-5 error rates were 37.5% and 17.0%, respectively. The neural network consists of 60 million parameters, 650,000 neurons, consisting of 5 convolutional layers plus 3 fully connected layers. To reduce overfitting, the Dropout strategy was used. At the same time, we used this model to participate in the ILSVRC-2012 competition. Compared with the second TOP-5 error rate of 26.2%, we won the competition with 15.3%.
1.PROLOGUE
Ynn LeCun and his partner had an article on neural networks that was rejected at the top conference, when researchers believed that there was still a need to artificially design features. 1980s Neuroscientists and physicists believe that hierarchical structural feature detectors are more robust, but they don't know what features the hierarchical structure will learn. At that time, some researchers found that the multi-layer feature detector can be effectively trained by the BP algorithm. For each image, the performance of the classifier depends on the weight at each connection point.
Although BP solved the problem of training, it still could not meet the expectations of people at that time. Especially when the network structure was very deep, it could not get good results, so people felt very difficult at that time, but after 2 years, we found that This is wrong, mainly because there are not enough data sets and enough computing power.
2.IntroducTIon
The main contributions of this paper are as follows:
1. We trained a convolutional neural network on ImageNet and achieved the highest accuracy at present.
2. We wrote a 2D convolution-based GPU optimization implementation and opened it up.
3. Use ReLU, multi-GPU training, local generalization to improve performance and shorten training time
4. Using Dropout, data augmentation to prevent overfitting
5. Using a 5-layer convolution plus a 3-layer fully-connected layer, the structure is also important, reducing network depth performance will be worse
(Because of the limitation of computing power, I used 5 3GB GTX580 GPUs to train for 5-6 days)
3. The Dataset
ImageNet is a high-resolution image with more than 15 million tags, which are divided into 22,000 categories, mainly from the Internet, manually tagged. The ILSVRC competition uses a subset of it, close to 1000 categories, with an average of 1000 images per class, a total of 1.2 million training images, 50,000 verification images, and 150,000 test set images.
ILSVRC-2010 is the only version of the test set that is also tagged, so we mainly use this data set to experiment, but we also participated in the ILSVRC-2012 competition.
ImageNet only has 2 indicators, top-1 and top-5. Top-5 means that the correct category does not appear in the top 5 most likely categories. Because ImageNet contains images of different resolutions and the system requires fixed-size images, we downsample the dataset to 256x256. For a rectangular image, we first program the short edge 256 and then intercept a 256x256 region at the center. Except for the mean value of each pixel minus the training, we don't do any preprocessing on the image.
4. The Architecture
The structure mainly consists of 8 layers, 5 layers of convolutional layers, and 3 layers of fully connected layers. Below are some new and uncommon features of our network. We explain the order according to their importance.
4.1. RecTIfied Linear Unit nonlinearity
On a simple 4-layer convolution network, the tanh function trains up to 6 times faster than the tanh function, so here we use ReLUs to train the neural network to speed up the training to cope with overfitTIng.
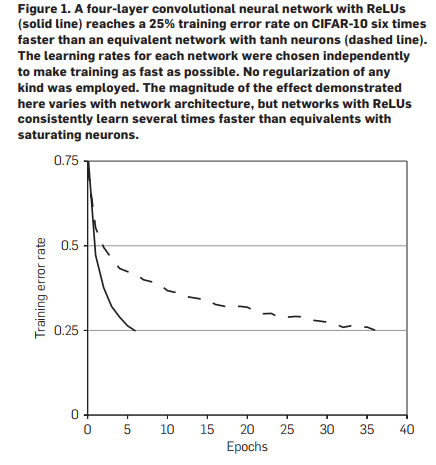
4.2. Training on mulTIple GPUs
A single GTX580 has only 3GB of memory (since the training training image size has been fixed to 256) so this limits the maximum size of our neural network. Experiments have shown that 1.2 million training samples are sufficient for the training network, but too large for a GPU, so we used two parallel GPUs to train, split the training parameters into two, and only let They communicate at a fixed layer, for example, the input of the third layer of convolutional layer comes from the entire second layer, and the input of the fourth layer only comes from the third layer of the same GPU, which is compared with The general parameters were trained on only one GPU, which was reduced by 1.7%, 1.2% of top-1, top-5, respectively, and also slightly accelerated the training speed.
4.3. Local response normalization
Although ReLUs does not need to generalize the input to prevent saturation, learning can be done when the input is positive, but we still find that adding local normalization can help improve the generalization ability of the model.
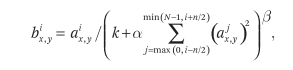
Using the above formula, the relevant parameters are adjusted by the verification machine. In the text, k = 2, n = 5, α = 10e-4, and β = 0.75 are used. We apply normalization to ReLUs at some specific layers. Experiments have shown that this can reduce 1.4%, 1.2% top-1, top-5, respectively. And the simple 4-layer convolutional network reduced the normal error rate on Cifar10 from 13% to 11%.
4.4. Overlapping pooling
The pooling operation with overlapping regions is reduced by 0.4%, 0.2% of top-1, top-5, respectively, and there is a slight possibility of over-fitting.
4.5. Overall architecture
Because of the dual GPU training, the second, fourth, and fifth convolutional layers are only concatenated with the same GPU, and the third-tier convolutional layer is fully connected to the second. The LRN layer is used in the first and second convolution layers. The maximum pooling layer is used in layers 1, 2, and 5. ReLU is used in every convolutional layer and full convolutional layer.
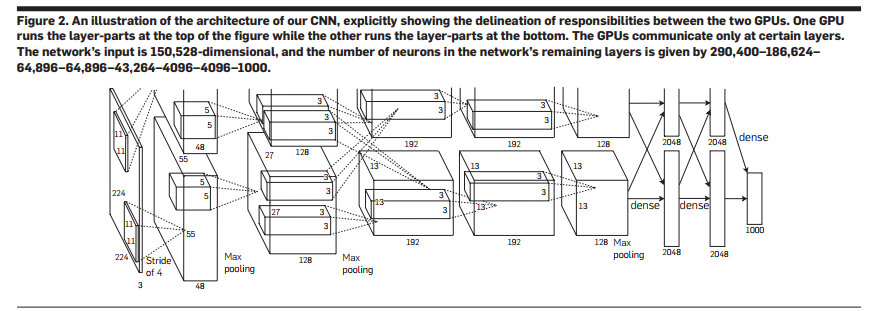
5. Reducing Overfitting
5.1. Data augmentation
The first way to augment is to randomly clip a 224x224 image on a 256x256 image and use the horizontally flipped samples to train the network. In the test, we cut the picture into 224x224 size with 4 corners and the center and flip it horizontally (one picture becomes 10 pictures). After inputting into the network, add the softmax values ​​of 10 pictures to average and output the final result. .
The second mode of augmentation is to change the value of the image RGB channel. This method reduces the top-1 accuracy by 1%.
5.2. Dropout
The droppedout layer does not participate in forward propagation and backpropagation, so that the structure of the network is different when each sample is trained. We use a 0.5 probability dropout in the first two layers of the fully connected layer, which also makes iteration The number of times needs to be doubled for training to converge.
6. Details of learning
The random gradient descent (SGD) algorithm was used for training. Batch size = 128, momentum = 0.9, weight decay = 0.0005. Experiments have shown that adding a decimal value to the weight dacay is important for training. It is more than just a regularizer. It can also reduce the training error rate.
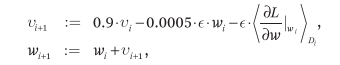
We initialize a Gaussian distribution with a zero mean, standard deviation of 0.01, and set the offset of the 2nd, 4th, and 5th convolutional layers and the full convolutional layer to a constant of 1. The other layers are set to a constant of 0, and the learning rate starts from 0.01. From the beginning of the training to the end of the training, the learning rate dropped by a factor of 10 by three times (basic 30 epoches dropped once) and trained for 90 epoches.
7. Results
It is also very interesting to note that the two GPU training pieces are mainly color information, and one piece is mainly outline information.

8.Discussion
It is worth mentioning that our network will degrade any of the convolutional layers. Removing any middle layer will reduce the top-1 accuracy by 2%, so the depth of the network is also important to our results.
Hanzhong Hengpu Photoelectric Technology Co.,Ltd , https://www.hplenses.com