"Tianjie Xiaoyu is as crisp as a grass, and the grass color is close to nothing." From Han Yu's two poems, it can be seen that people's semantic understanding of the image content does not rely on fine-grained supervision information for assistance. In contrast, in the field of machine learning, the current task of semantic segmentation depends on a large amount of finely labeled data. The Internet, as the most abundant data source, has attracted the attention of relevant practitioners. However, if you want to use these data, you will face enormous labeling pressure.
Therefore, two points of thinking are triggered: First, can we combine keyword information as an aid to learn knowledge directly from the web without the need for fine manual annotation? Second, can you use class-independent clues to generalize it to all other class objects after training on a dataset labeled with a small number of classes?
In this article, Professor Cheng Mingming from Nankai University will introduce the current research progress from these two points.


Traditional pixel-level semantic understanding methods usually require a large amount of finely labeled image training. The figure above shows an example of the ADE20K data set, which contains 210,000 images of finely annotated objects, which were annotated by Professor Antonio’s mother for a long time.

Professor Antonio once joked at CVML2012: "My mother marked such a high-quality data set, I really hope I have more mothers." This is a joke, but it also illustrates the importance of building a data set and the amount of time and effort required to build it.

Looking back on our growth process, from small to large, our parents have never made such fine annotations to help us identify and recognize the world around us. The usual way of learning is that our parents show us a flower and tell us it is a flower, then we can easily know which areas and which pixels correspond to this flower. So how do we use this information to learn the semantic content represented by each pixel? At the same time, can such a kind of information help us better understand the content of the image and provide a fine semantic understanding of the image?

Our research content is how to use a similar mechanism to remove the dependence on fine labeling information. In life, when we want to understand an object that we are not familiar with, such as a fruit, usually we only need to search the Internet and observe a few pictures, we can fully understand this fruit, and can Easily identify the corresponding target and target area. Can the computer have the ability to learn knowledge directly from the web without the need for fine manual annotation?

There are many related tasks that can help pixel-level semantic understanding, such as salient object detection: given an image, it is critical to find and find salient objects in the image. For example, when we use keywords to retrieve images on the Internet, there is usually a strong correlation between the retrieved images and keywords. Through salient target detection, we can assume the semantic information of the salient regions corresponding to the detection results It is the key word, of course, this assumption is noisy or wrong.

In addition to saliency detection, there are also information such as edge detection of images and over segmentation of images. This information is category-independent, and a good general model can be trained from very few data sets. For example, edge detection, we can train a good edge detection model from the BSD dataset with only 500 data. The edge can describe the boundary of the object well, which can reduce the dependence on fine annotation. Similarly, over-segmentation and saliency detection have the same effect. A straightforward idea is whether we can use these category-independent cues to train on a dataset with a small number of categories and generalize it to all other categories of objects? Even if it is an object that we have not seen, we can find the area corresponding to the object without knowing the type of the object.

Following this idea, we have our first work: salient object detection, which was published in 2017 CVPR and 2018 TPAMI. Below we introduce the work.
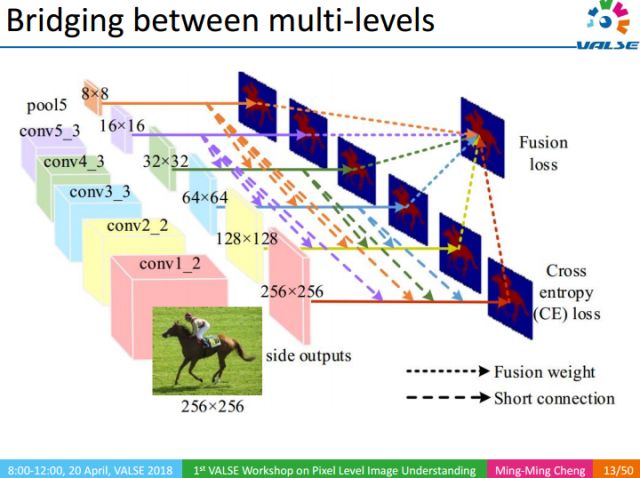
The core idea of ​​this work is to multi-scale Deeply Supervised way, fuse the information of different scales, and detect the areas of salient objects from multiple scales. Because the low-level features and high-level features in CNN are better at making detailed descriptions and global positioning, but not comprehensive enough, it is difficult to obtain high-quality segmentation results. We enrich the low-level information by passing the top-level information down, so that it can be well positioned and maintain details.

Here are some example results. Our focus is not to explain how to do salient object detection, but to convey an important message that through salient object detection, we can segment salient objects in the image very well. This discovery can help machines learn pixel-level semantic segmentation directly from the web.

The above figure shows the detection results of our method in different scenes. It can be seen that even in the case of low contrast and complex objects, our salient object detection method can still find the area of ​​the object well.
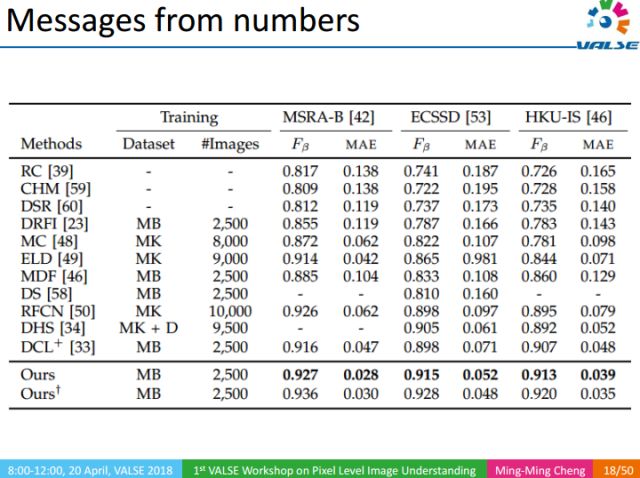
At the same time, in the common data set, the Fβ performance index of our algorithm exceeds 90%. In order to verify the generalization ability of the algorithm, we conducted cross-validation between different data sets. The experimental results show that our salient target detection method can learn category-independent tools from data with a small number of category annotations (such as 1000 categories). And this tool can also segment it from the image without knowing the type of the object.

This method also has some shortcomings. For example, when the scene is particularly complex (such as a motorcycle) or the saliency object is particularly vague (such as the right half of the cat), our method will also fail.
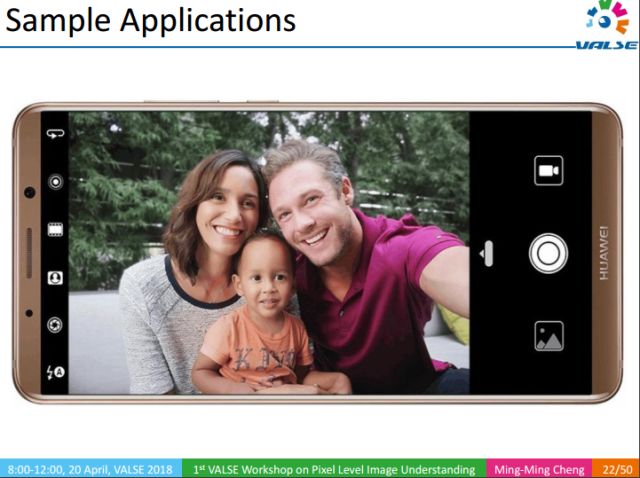
As mentioned earlier, the Fβ performance of our method on multiple data sets can exceed 90%, which can well locate salient objects. The picture above is an application of our work, which is applied to the smart photography of Huawei mobile phones: during the process of taking pictures, it automatically finds the foreground target, which enables the camera to take pictures with a large aperture. The traditional large-aperture photography requires a SLR camera (extra physical burden) to obtain the artistic effect of the combination of virtual and virtual reality.

Another important category-independent information is edge detection. The edges help to locate the object. As shown in the figure above, without knowing the specific type of animal, we only need to know that there is an animal in the image (keyword level label), we can find the area corresponding to the animal. Below we introduce the work published in CVPR 2017 (RCF).
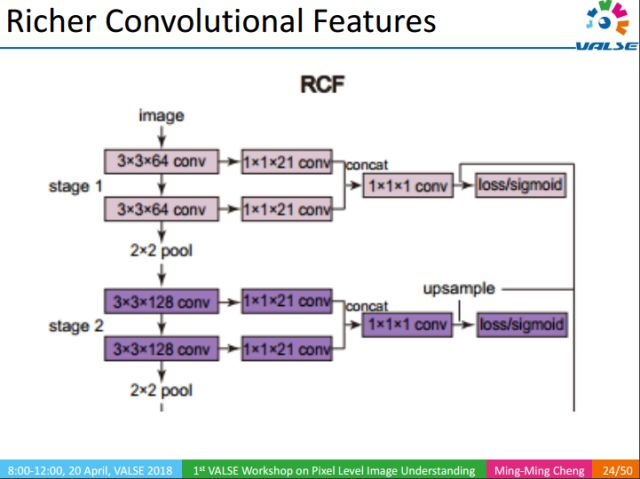
The core idea of ​​RCF is to use rich multi-scale features to detect edges in natural images. In the early classification tasks, the middle layer is often ignored, and later people use the middle layer through the 1x1 convolutional layer. But these works only use the last convolutional layer of each stage, in fact each convolutional layer is useful for the final result. RCF fused all convolutional layers through 1x1 convolutional layers. This fusion effectively improves the edge detection effect.

For example, in the straw area of ​​the image, traditional methods such as canny operator will have very high response in these areas, but RCF can suppress these responses well. There are also areas such as sofas, coffee tables, etc. where it is difficult to observe the edge. RCF can detect the edge robustly, and the result is even clearer than the original image structure. This provides us with a foundation for learning directly from the Web.
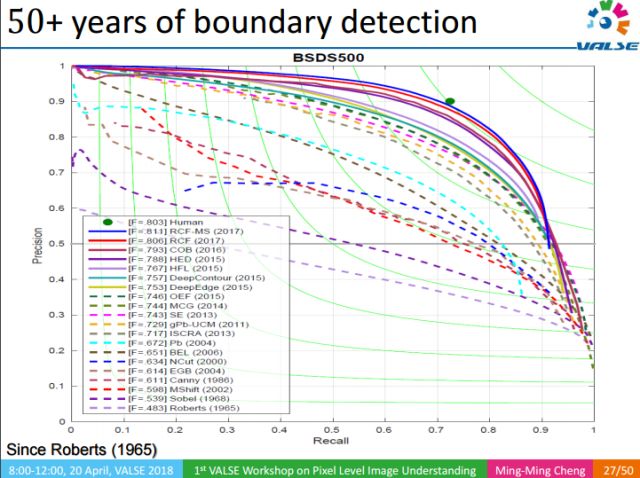
As one of the earliest research problems in computer vision, edge detection has experienced more than 50 years of development, but RCF is the first to be able to achieve real-time detection, and its performance exceeds the manual labeling work on the Berkeley data set. Of course, this does not mean that RCF surpasses humans. As long as people are given enough time to think carefully, people can mark it better, but RCF is undoubtedly a major breakthrough. And to train such a powerful edge detection model, only a data set containing 500 images is used, which is very enlightening for us to learn directly from the Web.
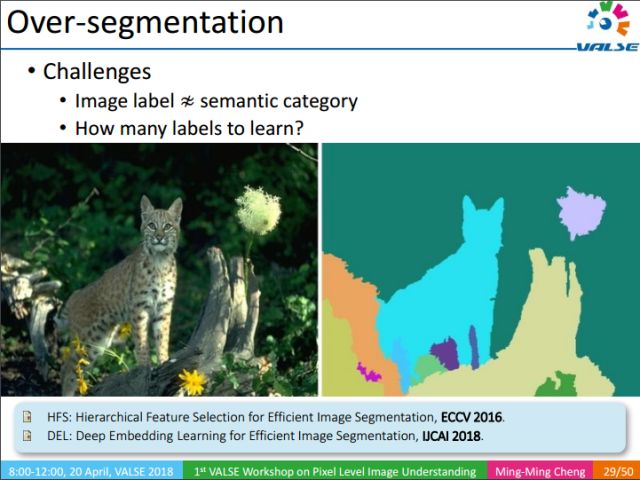
Good over-segmentation results can effectively assist pixel-level semantic understanding (especially when there is little manual annotation data). Over-segmentation (over segmentation) is also an important category-independent information. Although the result of over-segmentation in the above figure resembles semantic segmentation (semantic segmentation), it has essential areas. In semantic segmentation, each pixel has a clear semantic label, so we can learn the specific semantic information of each pixel through a neural network. Over-segmentation only divides the image into many different regions, and each region corresponds to a label. These labels have no definite semantic information, so given an image, we cannot determine how many regions each image can produce, nor how many labels (100, 1000, or 1000?) each image can produce. This question is for learning. Brought a lot of great difficulties. The following introduces our work published in IJCAI2018.
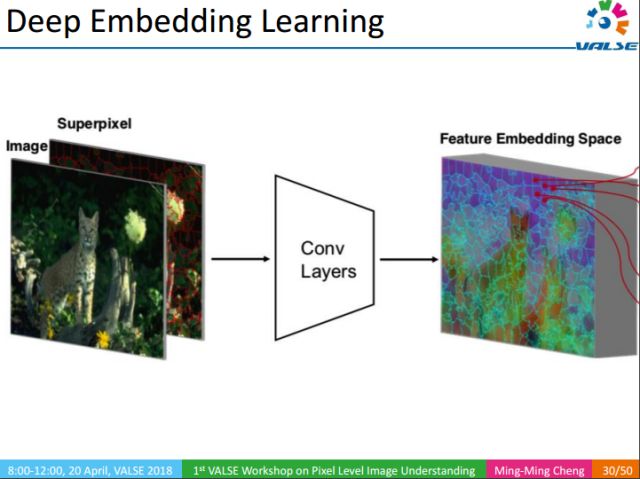
Our method does not directly correspond to pixels and labels, but first superpixelizes the image to improve the calculation speed, then extracts the convolutional features of the superpixels, and then pools the features of each superpixel to a fixed length Vector, and finally learn the distance between every two superpixels. When the distance between superpixels is less than a threshold, merge them. Compared with traditional methods, our method is simple, effective, and achieves good results, and can be processed in real time (50fps/s). This also provides support for learning pixel-level semantic understanding directly from the Internet.

With the above-mentioned category-independent low-level visual knowledge, we can do a lot of interesting analysis on the image. For example, we use keywords to retrieve images on the Internet, through salient object detection, we can detect the approximate position of the object in the image, and then through the edge, over-segmentation and other information can further refine the object's regional information. Eventually, a proxy groundtruth (GT) can be generated. This GT is not manually annotated. It is a guess that we use an automated method for the Internet image GT. This guess is likely to cover the corresponding area of ​​the keyword in the image, of course, there will be many errors in these areas. For example, when segmenting the bicycle in the figure above, our method often marks people, because usually bicycles appear with people.
So how to eliminate these errors?
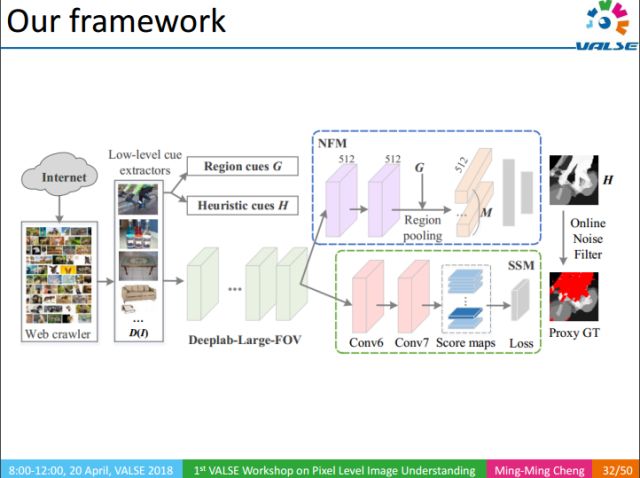
The flow of the whole method is as follows: 1 use keyword retrieval to obtain a large number of images; 2 use the underlying visual knowledge to obtain the image corresponding to the proxy GT; 3 use NFM to remove the influence of the noise area in the proxy GT on the training process; 4 finally obtain the semantics through the SSM part Segmentation result.
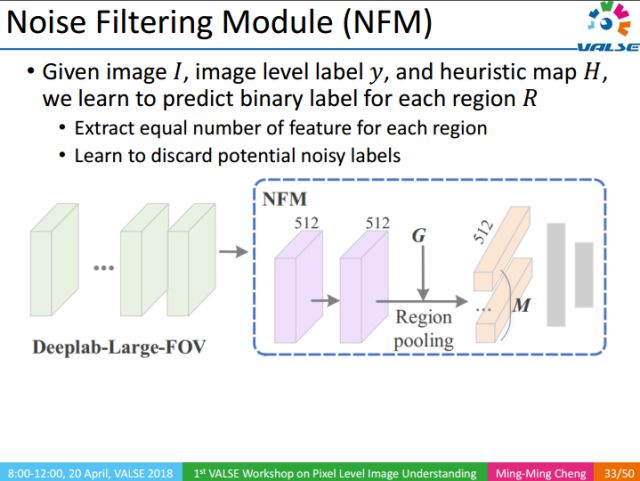
NFM (Noise Filtering Module): Noise filtering module, given the input image, uses image-level annotations and corresponding heuristic map to filter the noise area in the image Proxy GT.

The red area in the figure above is the identified noise area.
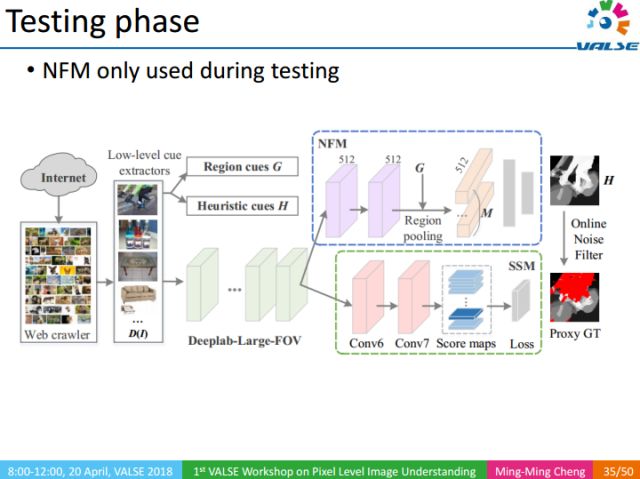
NFM, as a method of auxiliary training, is only used in the testing phase.
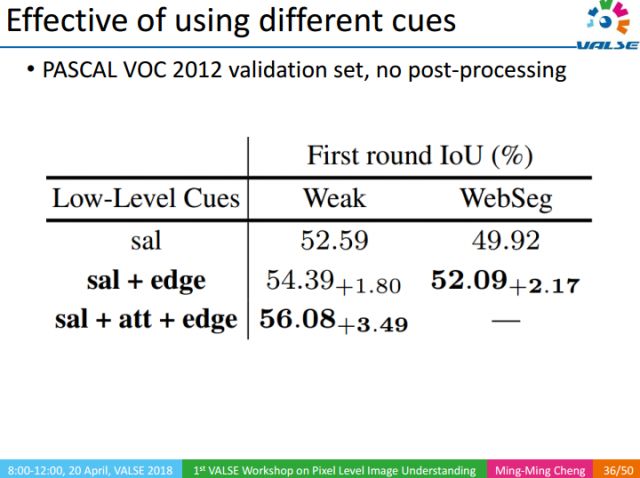
Through experiments, we separately verified the importance of the underlying visual knowledge. The experiment is divided into two categories, Weak indicates that the image has only one keyword-level annotation, and WebSeg indicates that the image does not have any manual annotation. In fact, there are many types of low-level visual knowledge. We only show three types here, namely Saliency object Detection (sal), Edge, Attention (att). Attention is a top-down information, which requires keyword-level annotation information. Since WebSeg does not use any manual annotation, there is no attention in WebSeg's experiment.
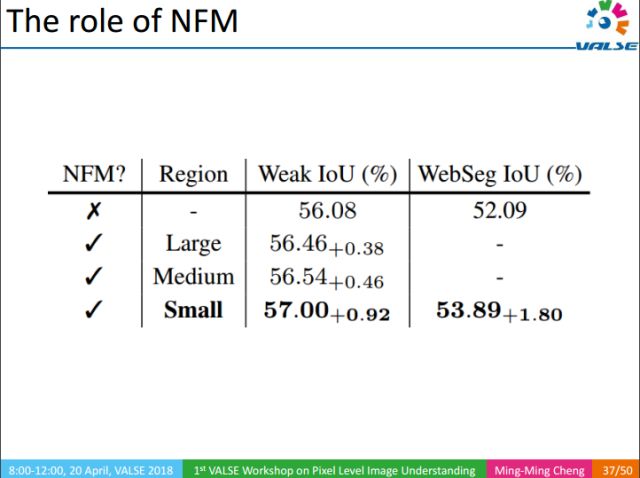
Similarly, we also verified the effectiveness of NFM. It can be seen that NMF can improve the accuracy of IoU.
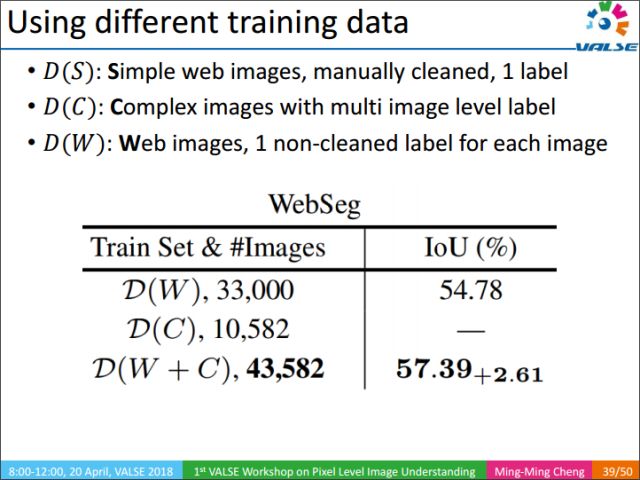
In the training process, the training data can be divided into three categories, D(S): the image content is simple, each image has a manually reviewed image-level annotation; D(C): the image content is complex, each image has more An approved image-level annotation; D(W): The content of the image is uncertain, and each image has an unaudited annotation.
The above table lists the different performances corresponding to different training set combinations.
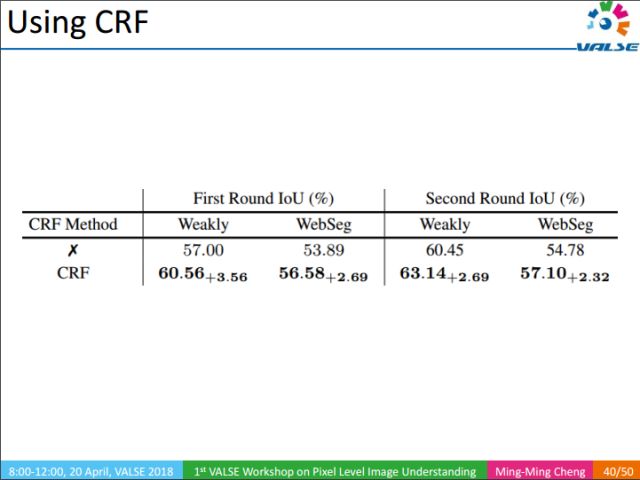
Using CRF can further improve the accuracy of the results.

The above picture is the result of our experiment. From left to right, we can see the importance of NFM and CRF respectively. Overall, our method can directly learn from Web images and get very good results of semantic segmentation.
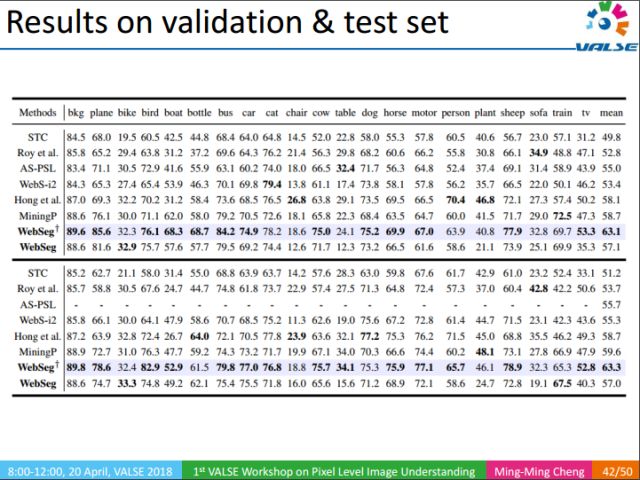
The above table is the experimental results at PASCAL 2012. After using a lot of low-level visual knowledge, our method can achieve an average IOU of 63%, which is a big improvement from 58% of the best results on CVPR last year.
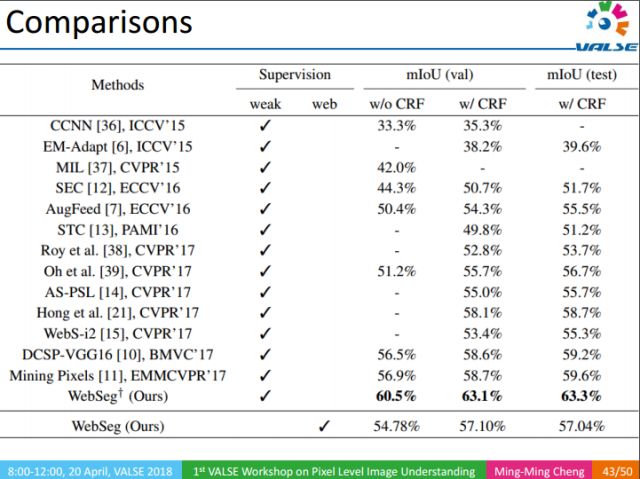
Another very meaningful result is that we can still achieve 57% of results without using explicit manual annotation. This result actually surpasses many weak supervision methods in CVPR 2017. In fact, the labeling of weakly supervised information also takes time and effort. In contrast, our method does not require any manual labeling. In the direction of directly letting the machine learn pixel-level semantic segmentation from the Web, we have only made a preliminary attempt, but it can exceed most of the results of CVPR 2017's weak supervision on the PASCAL VOC-level dataset. Exciting. In the long run, this is a very meaningful research direction.

Summarizing the entire report, we have raised a very meaningful and challenging visual problem: how to learn semantic segmentation directly from the Web without manual annotation. At the same time, we also proposed an online noise filtering mechanism to allow CNN to learn how to remove the noisy areas in the Web learning results. The purpose of the entire work is to reduce or remove the dependency of pixel-level semantic understanding tasks on finely labeled data.

We have only touched the fur of the pure web-based supervised learning field at present, and there are many work worth studying in the follow-up, such as:
1. How to make effective use of images. In the current work, Web images are processed directly regardless of their quality, and no more learning is done. We have to think about whether we can improve the efficiency of using web images through learning;
2. Or is it possible to associate the underlying visual knowledge with its corresponding keywords, such as Salient Object Detection, which was not previously associated with its corresponding label, can this correlation further improve the results?
3. And, improve the performance of the underlying visual knowledge independent of category, such as edge detection, over segmentation, etc.;
4. In addition, there are some other tasks of pure Web supervision.
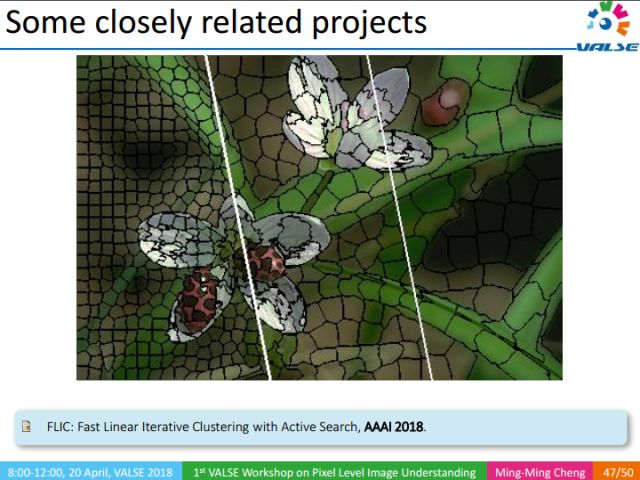
We have also done a lot of work related to the underlying visual knowledge, such as Over-segmentation.

Salient-Instance Segmentation is also a kind of category-independent information. Although it does not know the object category, it can segment a significant instance.

Hybrid Single Phase Solar Inverter
A Hybrid inverter is an intelligent inverter that enables the storage of excess solar energy in a battery system for self-use. Hybrid inverters function like a common grid-tie solar inverter but can generally operate in one of several different modes depending on the application, this includes battery backup mode which provides a limited level of backup power in the event of a blackout. Most hybrid inverters can also operate without a battery and function just like a grid-tie solar inverter by exporting excess solar energy to the utility grid.

Most hybrid inverters can be programmed to function in four different modes:
Hybrid mode - Stores excess solar energy during the day to be used in the evening to increase self-sufficiency.
Backup mode - Functions like a normal solar inverter when the grid is connected and automatically switches to backup power mode during a grid outage
Off-grid mode* - Operates much like an off-grid inverter and uses excess solar to charge the battery and power the loads without a grid-connection.
Grid-tie mode - Functions like a normal solar inverter (no battery)



On Off Grid Solar Inverter,MPPT Hybrid Solar Inverter,High Frequency Hybrid Solar Inverter,Parallel Hybrid Solar Inverter,Single Phase Solar Inverter
Shenzhen Jiesai Electric Co.,Ltd , https://www.gootuenergy.com