The craze for deep learning is still surging, and the neural network has once again become a special concern for the industry. The future of AI is promising, and deep learning is affecting our daily lives. Recently, Stanford University shared a paper on his exploration of the interpretability of deep neural networks. Let's see if he understands it!
Recently, Mike Wu, a Ph.D. student in computer science at Stanford University, published a blog introducing his exploration of the interpretability of deep neural networks, mainly referring to tree regularization. The paper "Beyond Sparsity: Tree RegularizaTIon of Deep Models for Interpretability" has been accepted by AAAI 2018.
In recent years, deep learning has quickly become an important tool in the industry and academic circles. Neural networks are once again becoming advanced technologies for solving image recognition, speech recognition, text translation, and other difficult problems. In October last year, Deepmind released a stronger version of AlphaGo, which can defeat the best human players and robots from the beginning, indicating that the future of AI is promising. In the industry, companies such as Facebook and Google have integrated deep networks into computing pipelines, relying on algorithms to process billions of bits of data per day. Startups such as Spring and Babylon Health are using similar methods to disrupt the medical field. Deep learning is affecting our daily lives.
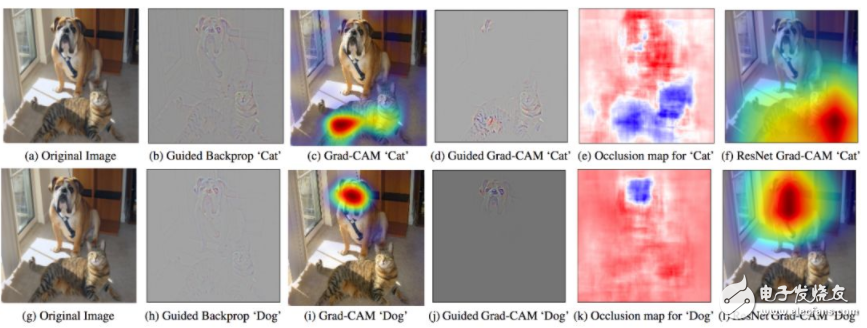
Figure 1: GradCam - Use the gradient of the target concept to highlight important pixels to create a visual interpretation of the decision.
But deep learning is a black box. When I first heard about it, it was very confusing. After a few years, I am still exploring a reasonable answer. Trying to explain modern neural networks is difficult, but crucial. If we are going to rely on deep learning to create new AIs, process sensitive user data, or prescribe drugs, then we must understand how these models work.
Fortunately, academics have also put forward a lot of understanding of deep learning. Here are a few examples of recent papers:
Grad-Cam (Selvaraju et. al. 2017): Generates a thermogram using the gradient of the last convolutional layer, highlighting important pixels in the input image for classification.
LIME (Ribeiro et. al. 2016): Approximating DNN predictions using a sparse linear model that easily identifies important features.
Feature Visualization (Olah 2017): For images with random noise, optimize the pixels to activate specific neurons in the trained DNN to visualize what the neurons learned.
Loss Landscape (Li et. al. 2017): Visualize DNN Try to minimize the non-convex loss function and see how the architecture/parameters affect the loss.

Figure 2: Feature visualization: An image is generated by optimizing activation of a particular neuron or set of neurons (Olah 2017).
As can be seen from the above examples, the academic community has different opinions on how to interpret DNN. Is the effect of isolating a single neuron? Visualize the loss situation? Feature sparsity?
1500Puffs Disposable Vape,Disposable Vapes Device,Disposable Vape Pen,Puff Double Disposable Vape
Shenzhen Uscool Technology Co., Ltd , https://www.uscoolvape.com