Introduction
For a software developer, you may have heard of an FPGA. Even in college course design, you may have used an FPGA to perform computer architecture-related validation, but for its first impression it may feel that this is a hardware engineer's job.
At present, with the rise of artificial intelligence, GPUs have taken the stage of history through deep learning, and with all kinds of business in full swing, it has its presence from training to inference. With this wave, FPGA is slowly moving toward the data center and playing its advantages. So let's talk about how FPGAs can make programmers more user-friendly development without writing annoying RTL code. You can easily implement unit test without using VCS or simulation software such as Modelsim.
The change of this programming idea is realized because FPGA uses OpenCL to realize programming. The programmer only needs to add appropriate pragma to achieve FPGA programming through C/C++. In order for FPGA applications that you implement with OpenCL to have higher performance, you need to be familiar with the hardware described below. In addition, the compiler optimization options will be introduced to help your OpenCL application better implement the RTL transformation and mapping, and deploy it to the FPGA.
FPGA Overview
FPGA is a high-specification integrated circuit that can achieve unlimited precision function function by continuous configuration and splicing, because unlike CPU or GPU, the bit width of basic data types is fixed, on the contrary, FPGA can do very much. flexible. In the process of using FPGA, it is especially suitable for some low-level operations, such as bit masking, shifting, addition, etc., which can be very easily implemented.
In order to achieve parallel computing, the FPGA internally contains look-up tables (LUTs), registers, on-chip memory, and hard arithmetic cores (such as digital signal processor (DSP) blocks). The modules inside these FPGAs are connected together through a network. Through programming, the connections can be configured to implement specific logic functions. This reconfigurable nature of the network connection provides the FPGA with high-level programmable capabilities. (FPGA programmability is reflected in changing the connection between the various modules and logic resources)
For example, look-up tables (LUTs) embody the FPGA programmability, which is equivalent to a program memory (RAM). The 3-bits input LUT can be equivalently interpreted as a memory with a 3-bit address line and 8 1-bit memory cells (an 8-length array with 1 bit per element in the array). Then when the 3-bits digital bitwise AND operation is required, the 8-length array stores the bitwise result of the 3-bits input number, which is a total of 8 possibilities. When a 3-bits bit-wise XOR is required, the 8-length array stores the bitwise XOR result of the 3-bits input number. There are a total of 8 possibilities. In this way, 3-bits bit-wise operations can be obtained within one clock cycle, and the bit-wise operations of different functions are completely programmable (equivalent to modifying the values ​​in the RAM).
A 3-bits input LUT implements a bit-wise AND example:
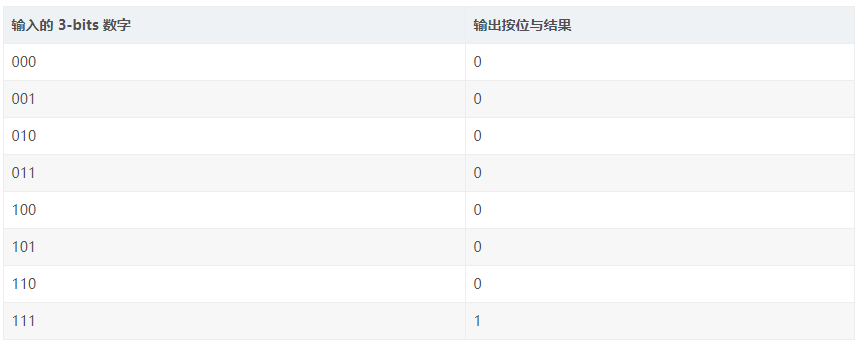
Note: 3-bits input LUT lookup table
The three-input bitwise AND operation we see, as shown below, is implemented within the FPGA through a LUT.
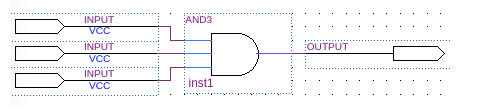
As shown above, a 3-input, 1-output LUT implementation is shown. When LUTs are connected in parallel or in series, more complex logic operations can be implemented.
Traditional FPGA development
Comparison between traditional FPGA and software development
For traditional FPGA development and software development, the tool chain can be easily compared by the following table:
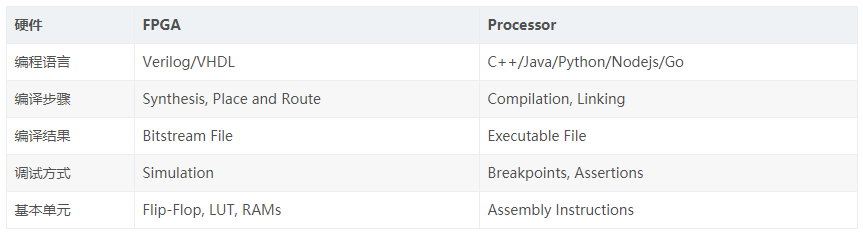
Note: Comparison of traditional FPGA and software development table
Focus on the synthesis phase of the compilation phase, which is quite different from the compilation of software development. General processor CPUs, GPUs, etc., are already manufactured ASICs, and their respective instruction sets can be used. But for FPGAs, everything is blank, there are only parts and components, nothing, but you can create any circuit in its own form, and the degree of freedom is very high. This degree of freedom is an advantage of FPGAs and a disadvantage in the development process.
Writing here reminds me of a stalk in the recent "Mysterious Programmers":



Note: The comic source "Mysterious Programmers 56" by West Joe
Traditional FPGA development is like Linux when it was 10 years old. To eat a cake, you need to start processing raw materials. This is the state of the FPGA. If you want to implement an algorithm, you need to write an RTL. You need to design the state machine and you need the correctness of the simulation.
Traditional FPGA development
Complex systems, which require the use of a finite state machine (FSM), generally require the design of the three parts of the logic contained in the following diagram: combinational circuits, sequential circuits, and output logic. What is the next state is obtained by the combinational logic, the sequential logic is used to store the current state, the output logic is mixed and the sequential circuit is obtained, and the final output result is obtained.
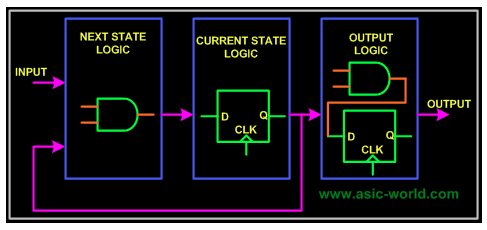
Then, for the specific algorithm, design the flow of logic in the state machine:
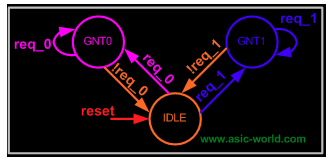
The implementation of RTL is this:
Module fsm_using_single_always (clock
, // clockreset
, // Active high, syn resetreq_0
, // Request 0req_1
, // Request 1gnt_0
, // Grant 0gnt_1 );//=============Input Ports========================== ===input
Clock,reset,req_0,req_1; //=============Output Ports========================= ==output gnt_0,gnt_1;//=============Input ports Data Type===================wire
Clock,reset,req_0,req_1;//============= Output Ports Data Type==================reg gnt_0,gnt_1; //=============Internal Constants======================parameter SIZE = 3
;parameter IDLE = 3'b001,GNT0 = 3'b010,GNT1 = 3'b100 ;//=============Internal Variables============= =========reg [SIZE-1:0]
State
;// Seq part of the FSMreg [SIZE-1:0]
Next_state ;// combo part of FSM//==========Code startes Here==========================always @ (posedge clock)begin : FSMif (reset == 1'b1) begin
State <= #1 IDLE; gnt_0 <= 0; gnt_1 <= 0; end else case(state) IDLE : if (req_0 == 1'b1) begin
State <= #1 GNT0;
Gnt_0 <= 1;
End else if (req_1 == 1'b1) begin
Gnt_1 <= 1;
State <= #1 GNT1;
End else begin
State <= #1 IDLE;
End GNT0 : if (req_0 == 1'b1) begin
State <= #1 GNT0;
End else begin
Gnt_0 <= 0;
State <= #1 IDLE;
End GNT1 : if (req_1 == 1'b1) begin
State <= #1 GNT1;
End else begin
Gnt_1 <= 0;
State <= #1 IDLE;
End default : state <= #1 IDLE;endcaseendendmodule // End of Module arbiter
The traditional RTL design is simply a nightmare for the programmer, dream, ah ~ ~ ~ tool chain is completely different, the development of ideas completely different, but also analysis of the timing, a Clock beats incorrectly, it is necessary to overturn, re-verify, everything They are too basic and not very convenient. So, let's go to the professional FPGAer. The OpenCL development FPGA described below is a bit like 25-year-old Linux. With a high level of abstraction. It will naturally be more convenient to use.
OpenCL-based FPGA development
OpenCL has injected fresh blood for FPGA development, a programming language for heterogeneous systems, and an FPGA that is the most heterogeneous implementation of an optional device. The execution process of the entire program is controlled by the CPU Host, and the FPGA Device is used as a means of heterogeneous acceleration. Heterogeneous architecture helps to free up the CPU and send the processing method that the CPU is not good to the Device. The typical heterogeneous devices currently include: GPU, Intel Phi, and FPGA.
What is OpenCL?
Note: Quoted from wiki
Open Computing Language (OpenCL) is a framework for writing programs that execute across heterogeneous planks consisting of central processing units (CPUs), graphics processing units (GPUs), digital signal processors (DSPs), field-programmable gate arrays (FPGAs) and other processors. Or hardware accelerators. OpenCL specifies a programming language (based on C99) for programming these devices and application programming interfaces (APIs) to control the platform and execute programs on the compute devices. OpenCL provides a standard interface for parallel computing using task-based and data -based parallelism.
The general idea is that: OpenCL is a framework for heterogeneous platform programming, the main heterogeneous devices are CPU, GPU, DSP, FPGA and some other hardware accelerators. OpenCL develops device-side code based on C99 and provides the appropriate API to call. OpenCL provides a standard parallel computing interface to support task parallelism and data parallel computing.
OpenCL Case Study
Here we use Altera's official website matrix multiplication case for analysis. Cases can be downloaded via the following link: Altera OpenCL Matrix Multiplication
The code structure is as follows:
.|-- common| |-- inc| | `-- AOCLUtils| | |-- aocl_utils.h| | |-- opencl.h| |-- options.h| | `-- scoped_ptrs.h| -- readme.css| `-- src| `-- AOCLUtils| |-- opencl.cpp| `-- options.cpp`-- matrix_mult |-- Makefile |-- README.html |-- device | `- - matrix_mult.cl `-- host |-- inc | `-- matrixMult.h `-- src `-- main.cpp
Among them, the FPGA-related code is matrix_mult.cl , which describes the kernel function. This part of the function generates the RTL code through the compiler and then maps it into the FPGA circuit.
The kernel function is defined as follows:
__kernel__attribute((reqd_work_group_size(BLOCK_SIZE,BLOCK_SIZE,1)))__attribute((num_simd_work_items(SIMD_WORK_ITEMS)))void matrixMult( __global float *restrict C, __global float *A, __global float *B, int A_width, int B_width)
The mode is relatively fixed, it should be noted that __global indicates that the data transmitted from the CPU is stored in the global memory, which can be FPGA on-chip memory resources, DDR, QDR, etc. This will be different depending on the OpenCL BSP driver of the FPGA. Num_simd_work_items indicates the width of the SIMD. Reqd_work_group_size indicates the size of the workgroup. For these concepts, refer to the OpenCL manual.
The function is implemented as follows:
// Declare a local store, one BLOCK__local float array A_local[BLOCK_SIZE][BLOCK_SIZE];__local float B_local[BLOCK_SIZE][BLOCK_SIZE];// Block indexint block_x = get_group_id(0); int block_y = get_group_id(1) ;/ / Local ID index (offset within a block) int local_x = get_local_id (0); int local_y = get_local_id (1);// Compute loop bounds a_start = A_width * BLOCK_SIZE * block_y; int a_end = a_start + A_width - 1; Int b_start = BLOCK_SIZE * block_x;float running_sum = 0.0f;for (int a = a_start, b = b_start; a <= a_end; a += BLOCK_SIZE, b += (BLOCK_SIZE * B_width)){ // read from global memory Take the corresponding BLOCK data to local memory A_local[local_y][local_x] = A[a + A_width * local_y + local_x]; B_local[local_x][local_y] = B[b + B_width * local_y + local_x]; // Wait for the Entire block to be loaded. barrier(CLK_LOCAL_MEM_FENCE); // Compute part, expands the computation units in parallel to form a multiplication addition tree #pragma unroll for (int k = 0; k < BLOCK_SIZE; ++k) { running_sum += A_local[ Local_ y][k] * B_local[local_x][k]; } // Wait for the block to be fully consumed before loading the next block. barrier(CLK_LOCAL_MEM_FENCE);}// Store result in matrix CC[get_global_id(1) * Get_global_size(0) + get_global_id(0)] = running_sum;
CPU simulation using FPGA
Simulate it, do not need to programer care about the specific timing is how to go, just need to verify the logic function, Altera OpenCL SDK provides the CPU simulation Device device function, using the following methods:
# To generate a .aocx file for debugging that targets a specific accelerator board$ aoc -march=emulator device/matrix_mult.cl -o bin/matrix_mult.aocx --fp-relaxed --fpc --no-interleaving default --board
In the above script, create a device executable for CPU debug with the -march=emulator setting. -g Add debug flag. —board is used to create a debugging file that fits the device. CL_CONTEXT_EMULATOR_DEVICE_ALTERA is the number of devices used for CPU emulation.
When the above script is executed, the output is as follows:
$ env CL_CONTEXT_EMULATOR_DEVICE_ALTERA=8 ./bin/host -ah=512 -aw=512 -bw=512Matrix sizes: A: 512 x 512 B: 512 x 512 C: 512 x 512Initializing OpenCLPlatform: Altera SDK for OpenCLUsing 8 device(s) EmulatorDevice : Emulated Device ... EmulatorDevice : Emulated DeviceUsing AOCX: matrix_mult.aocxGenerating input matricesLaunching for device 0 (global size: 512, 64)...Launching for device 7 (global size: 512, 64)Time: 5596.620 msKernel time ( Device 0): 5500.896 ms...Kernel time (device 7): 5137.931 msThroughput: 0.05 GFLOPSComputing reference outputVerifyingVerification: PASS
By setting Device = 8 at the time of simulation, the matrix of 8 devices running (512, 512) * (512, 512) is simulated and the final verification is correct. Then you can actually compile it on the FPGA device and run it.
Matrix Multiplication on FPGA Devices
At this time, you really need to download the code to the FPGA. At this time, you only need to do one thing. That is, use the compiler provided by the OpenCL SDK to adapt the *.cl code to the FPGA and execute the compile command as follows:
$ aoc device/matrix_mult.cl -o bin/matrix_mult.aocx --fp-relaxed --fpc --no-interleaving default --board
This process is slow and typically takes hours to 10 hours depending on the size of the resources on the FPGA. (At present, this time is too long to be solved temporarily, because the compilation here is actually a circuit that can work normally in the itinerary, and the software will perform the work of layout and wiring)
After waiting for the compilation to complete, the generated matrix_mult.aocx file is written to the FPGA on the ok.
Write the following command:
$ aocl program
At this time, you're done and you can run the host program:
$ ./host -ah=512 -aw=512 -bw=512Matrix sizes: A: 512 x 512 B: 512 x 512 C: 512 x 512Initializing OpenCLPlatform: Altera SDK for OpenCLUsing 1 device(s)
It can be seen that the matrix multiplication can operate normally on the FPGA and throughput is around 119 GFlops.
summary
From the above development process, OpenCL has greatly liberated the development cycle of FPGAer, and it is easier for software developers to get started. This is his advantage, but in the current development process, there are still some problems, such as: insufficient compiler optimization, there is a gap compared to the performance of RTL write; compile time to the Device side is too long. However, with the development of the industry, these will certainly progress slowly.
In addition, students who are interested in FPGAs or use FPGAs as their solution are welcome to discuss together.
Middle-low Level Lighting Sky Curtain
Middle-Low Level Lighting Sky Curtain,Ultra Transparency Display,Digital Signage Video Display,High Brightness Led Outdoor Lighting
Kindwin Technology (H.K.) Limited , https://www.ktlleds.com