Author: Nick Ni and Adam Taylor
One of the hottest topics in embedded vision today is machine learning. Machine learning covers a wide range of industry trends, not only in embedded vision (EV), but also in industrial Internet of Things (IIoT) and cloud computing. For those unfamiliar with machine learning, machine learning is often done through neural network creation and training. The term neural network is extremely broad and contains a significant number of distinct subcategories. The names of these subcategories are generally used to identify the specific type of network being implemented. These networks are modeled on the cerebral cortex, where each neuron receives input, processes input, and communicates it to another neuron. Thus a neuron typically consists of an input layer, multiple hidden inner layers, and one output layer.
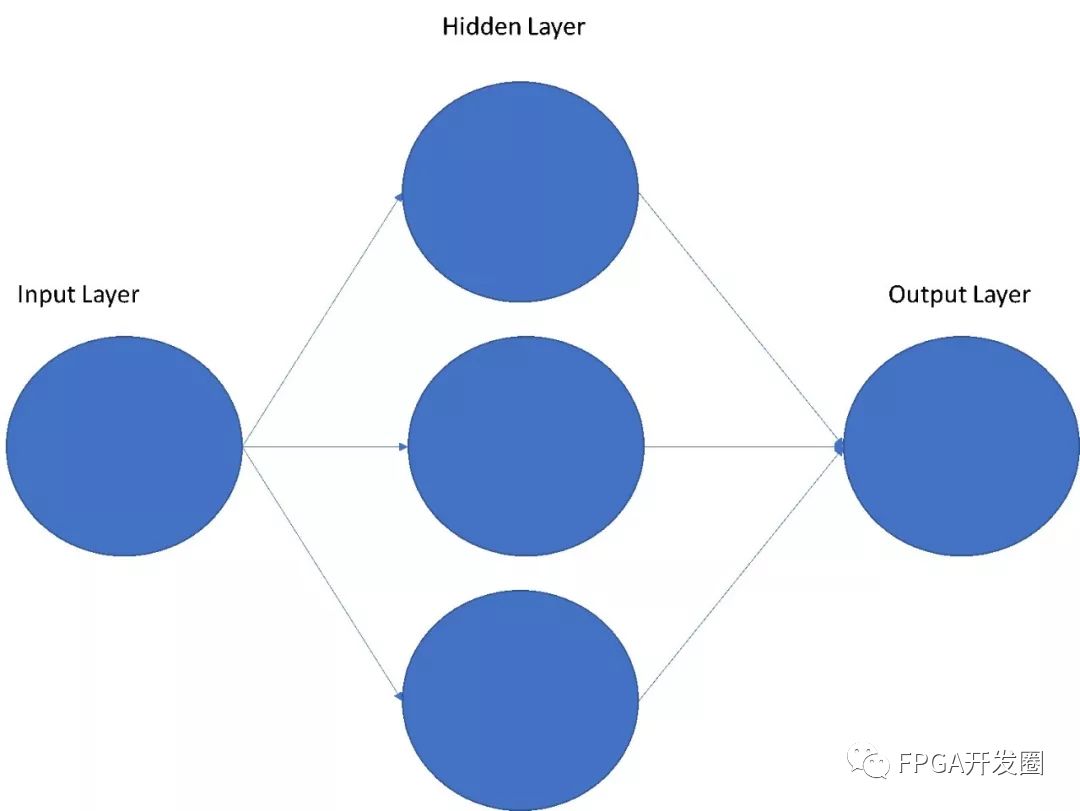
Figure 1: Simple neural network
At the simplest level, the neuron takes input, applies weights to the input, and then performs a transfer function on the weighted input sum. The result is then passed to another layer in the hidden layer or passed to the output layer. A neural network that passes the output of one stage to another and does not form a loop is called a feedforward neural network (FNN), and those that have feedback and contain a directed loop are called recurrent neural networks (RNN). . The neural network that is most commonly used in many machine learning applications is the Deep Neural Network (DNN). This type of neural network has multiple hidden layers that enable more complex machine learning tasks. In order to determine the weights and bias values ​​used for each layer, the neural network needs to be trained. During the training process, the neural network imposes a certain number of correct inputs and erroneous inputs, and uses the error function to teach the performance required by the network. Training deep neural networks may require a large data set to properly train the required performance.
One of the most important applications of machine learning is in the field of embedded vision, where systems are evolving from vision-enabled systems to vision-guided automation systems. Embedded vision applications differ from other simpler machine learning applications in that they use a two-dimensional input format. Therefore, in machine learning implementations, a network structure called Convolutional Neural Networks (CNN) is used because they are capable of handling two-dimensional inputs. CNN is a type of feedforward network with multiple convolutional and sub-sampling layers and a single fully connected network to perform the final classification. Given the complexity of CNN, they also belong to the deep learning category. In the convolutional layer, the input image is subdivided into a series of overlapping small modules. The result of the convolution is first created by the activation layer before being applied to the final fully connected network. The specific definition of a CNN network varies depending on the network architecture implemented, but it typically contains at least the following elements: • Convolution – used to identify features in the image • Corrected linear unit (reLU) – used to create an activation map after convolution Activation layer ◠Maximum pooling – subsampling between layers ◠Full connectivity - performing final classification
The weight of each of these elements is determined by training, and one of the advantages of CNN is that it is relatively easy to train the network. Generating weights through training requires a huge set of images, both objects that need to be detected and pseudo images. This allows us to create the required weights for CNN. Due to the processing requirements involved in the training process, the training process typically runs on a cloud processor that provides high performance computing.
frameMachine learning is a complex topic, especially when you have to start from scratch, define the network, network architecture, and generate training algorithms. To help engineers implement networks and training networks, there are industry standard frameworks available, such as Caffe and Tensor Flow. The Caffe framework provides machine learning developers with pre-training weights in a variety of libraries, models, and C++ libraries, as well as Python and Matlab bindings. The framework allows users to create networks and train the network without having to start from scratch to perform the required operations. For ease of reuse, Caffe users can share their models through the model zoo. The Model Zoo offers a variety of models that can be implemented and updated according to the specific tasks required. These networks and weights are defined in the prototxt file. When used in a machine learning environment, the prototxt file is the file used to define the inference engine.
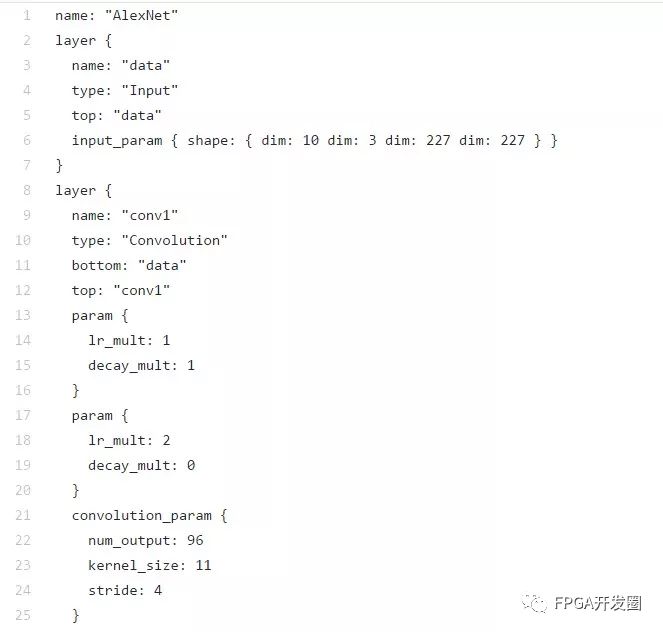
Figure 2: Example of a Prototxt file defining a network
Implement embedded vision and machine learningProgrammable logic-based solutions such as heterogeneous Xilinx All Programmable Zynq® -7000 SoC (system on a chip) and Zynq® UltraScale+TM MPSoC multi-processor system-on-chip (MPSoC) are increasingly used for embedded vision application. These devices combine a programmable logic (PL) architecture with a high-performance ARM® core in a processing system (PS). This combined system delivers faster response times, is extremely flexible for future modifications, and provides an energy-efficient solution. Low latency decision and response loops are extremely important for many applications. For example, visually guiding autonomous robots, response time is essential to avoid harm to people and cause damage to the environment. A specific way to reduce response time is to implement a visual processing pipeline using programmable logic and machine learning using a machine learning inference engine. Using programmable logic in this area reduces system bottlenecks compared to traditional solutions. When using a CPU/GPU-based approach, external DDR is required for each phase of the operation because images cannot be passed between functions within a limited internal cache. Programmable logic methods use internal ARM to provide on-demand caching, allowing streaming methods. Avoiding storing intermediates in DDR not only reduces the latency of image processing, but also reduces power consumption and even increases determinism because there is no need to share access with other system resources.
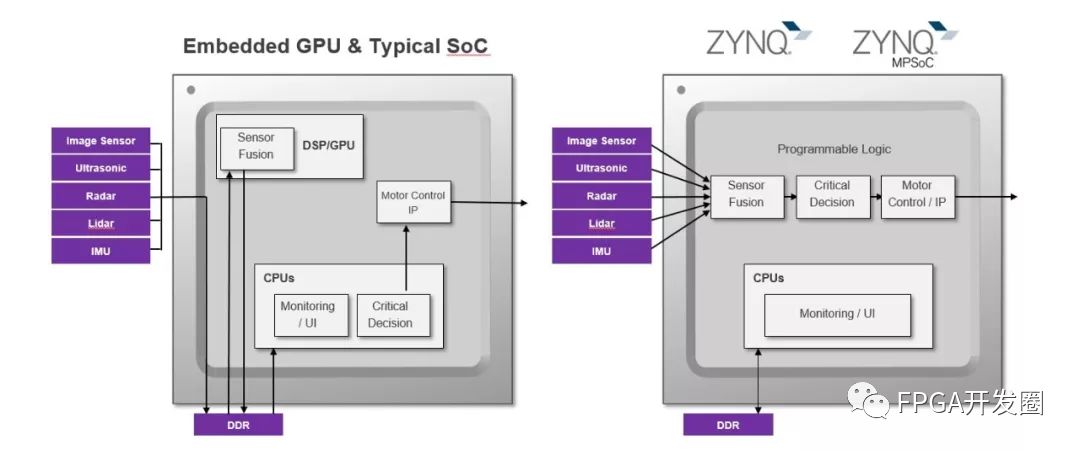
Figure 3: Benefits of Programmable Logic Implementation
Image processing algorithms and machine learning networks are easily implemented in heterogeneous SoCs using the reVISIONTM stack from Xilinx. Based on the SDSoCTM tool, reVISION supports both traditional image and machine learning applications. Inside reVISION, both OpenVX and Caffe frameworks are supported. To support the OpenVX framework, kernel image processing can be accelerated into programmable logic to create an image processing pipeline. At the same time, the machine learning inference environment supports a hardware optimization library in programmable logic to implement an inference engine that implements a machine learning implementation.
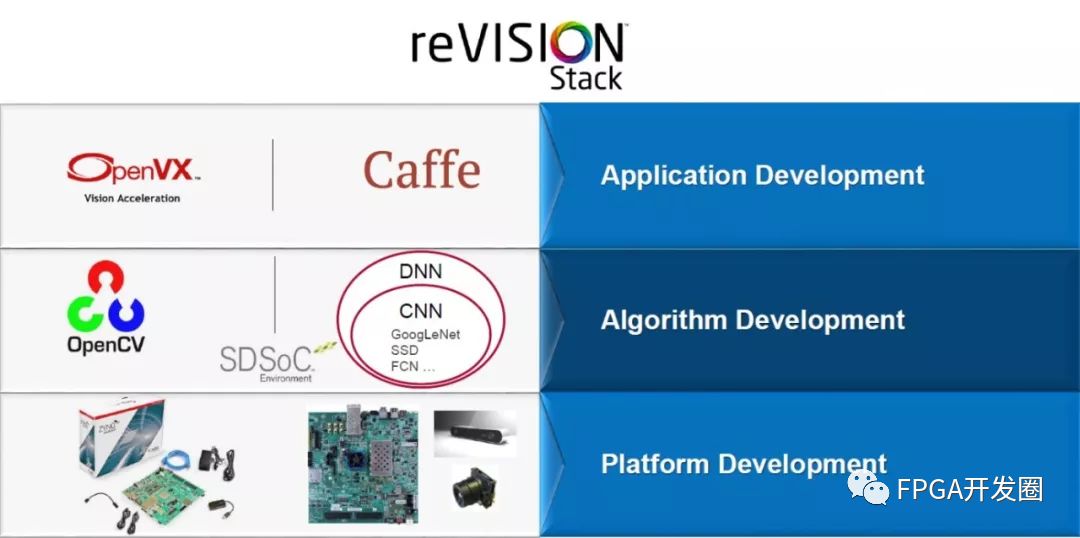
Figure 4: reVISION stack
reVISION provides integration with Caffe so that the machine learning inference engine is as simple as providing a prototxt file and trained weights, and the framework is responsible for handling the rest. The C/C++ scheduler running on the processing system is then configured with a prototxt file to speed up neural network inference on the hardware-optimized library in the programmable logic. Programmable logic is used to implement the inference engine, which includes features such as Conv, ReLu, and Pooling.
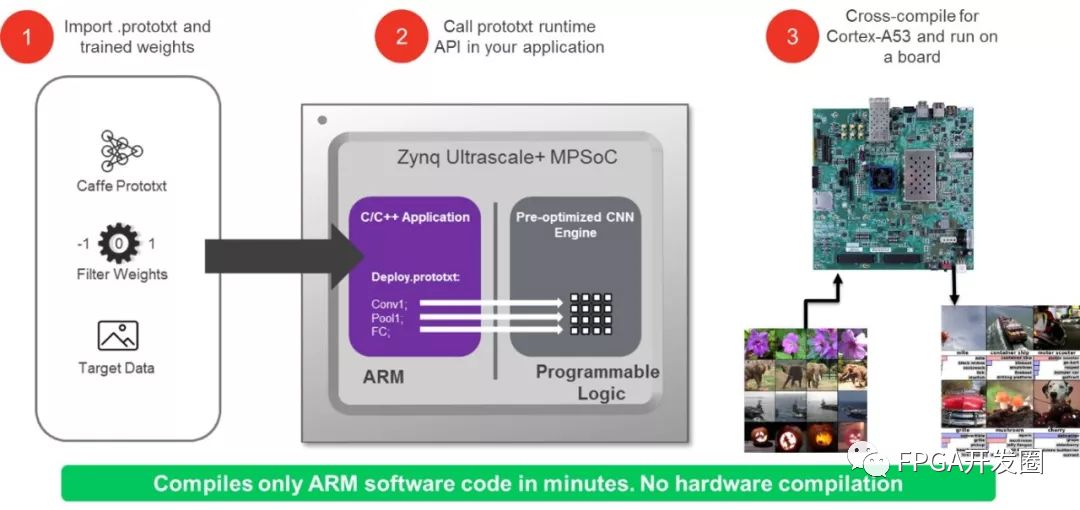
Figure 5: Caffe Process Integration
The numerical representation system used in the machine learning inference engine implementation also plays an important role in machine learning performance. Machine learning applications are increasingly using more efficient precision-precision fixed-point numerical systems, such as INT8 expressions. Compared to the traditional floating point 32 (FP32) method, the use of fixed point precision numerical systems does not cause significant degradation in accuracy. Because fixed-point math is significantly less difficult to implement than floating point, using INT8 can provide a more efficient and faster solution in some implementations. The use of fixed-point numerical systems is ideal for implementations in programmable logic solutions, and reVISION works with INT8 expressions in programmable logic. These INT8 expressions make it easy to use specialized DSP blocks in programmable logic. These DSP block architectures can implement up to two concurrent INT8 multiply-accumulate operations for execution when using the same core weights. This not only provides a high-performance implementation, but also reduces power consumption. As long as it is adopted, the flexibility of the programmable logic also facilitates the implementation of further reduced-precision fixed-point numerical expression systems.
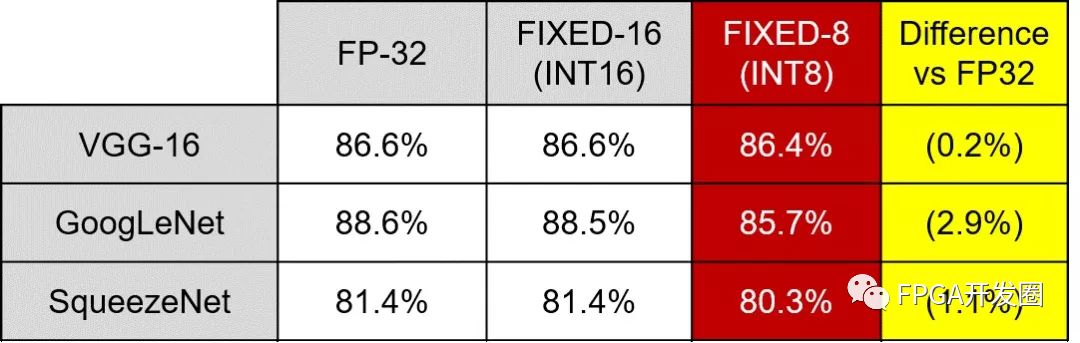
Figure 6: Network accuracy for different weight expressions.
Source: https://arxiv.org/pdf/1510.00149v5.pdf
Real performanceIn a real environment, the reVISION stack offers significant advantages. One of the application examples of using machine learning in embedded vision applications, such as vehicle collision avoidance systems. For re-improvement of Xilinx UltraScale+ MPSoC and related applications, SDSoC is used to accelerate the functions in programmable logic to optimize performance and significantly improve responsiveness. The difference in response time between the reVISION MPSoC and the GPU-based approach is quite obvious when both are used to implement the GoogLeNet solution. The reVISION design can detect potential collision events and start vehicle braking in 2.7ms (using a batch size of 1), while the GPU-based approach takes 49ms-320ms (depending on its implementation) (for large-scale scales) ). The GPU architecture requires a large batch size to achieve reasonable throughput, but at the expense of response time, and Zynq achieves high performance with very low latency at a batch size of one. This difference in reaction time can determine whether a collision occurs or not.
to sum upMachine learning will continue to be an important driver for many applications, especially in vision-oriented robots or so-called "collaboration robots." Heterogeneous SoCs that combine processor cores with programmable logic create highly efficient, responsive, and reconfigurable solutions. The introduction of a stack like reVISION brings the benefits of programmable logic to the broader developer community for the first time, while also reducing the development time of the solution.
Dc Relay,Dc Power Relay,Condenser Contactor,Voltage Protection Relay
NanJing QUANNING electric Co.,Ltd , https://www.quanningtrading.com